Manufacturing and Industrial · Customer Experience
Automate Field Service in Manufacturing with AI
For manufacturers, plant managers, supply chain leaders, quality teams, and industrial sales teams ready to move field service from manual operation to instrumented AI-native delivery. Below: the workflow we ship, the operating model that keeps it improving, the governance posture, and the commercial envelope.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native field service for manufacturing — From Discovery baseline to production traffic in 8-12 weeks, with the operating model — eval harness, reviewer UI, audit log, calibration cadence — handed over as part of Build, not deferred to Run. Expected delta on first time fix rate: +0.3.
Key facts
- Industry
- Manufacturing
- Use case
- Field Service
- Intent cluster
- Customer Experience
- Primary KPI
- first time fix rate, travel time, SLA attainment, and service margin
- Top benchmark
- CSAT (post-interaction): 4.1 / 5 → 4.4 / 5 (+0.3)
- Systems integrated
- ERP, MES, QMS
- Buyer
- manufacturers, plant managers, supply chain leaders, quality teams, and industrial sales teams
- Risk lens
- production downtime, quality escapes, worker safety, IP protection, and supplier reliability
- Engagement timeline
- Discovery 2.5 weeks → Build 7 weeks → Run continuous
- Team size
- 2 senior delivery (1 architect + 1 implementer)
- Discovery price
- $5k · 2-week sprint
- Build price
- $18k–$25k · 6-9 weeks
Primary outcome
increase field productivity and reduce repeat visits
What we ship
dispatch assistant, technician knowledge base, parts predictor, and visit summary workflow
KPIs we report on
first time fix rate, travel time, SLA attainment, and service margin
Why Manufacturing teams hire us for this
The instinct in manufacturing is to either build everything internally or sign a multi-year retainer with a consulting firm. Neither option is well-matched to the speed of model and tooling changes in 2026. A scoped, phased AI-native engagement on field service lets you move fast on the build while keeping option value on what comes next.
Zendesk and Salesforce CX research show that manufacturing customers tolerate AI-assisted service when the escalation path to a human is fast and obvious. We design the escalation surface before we design the automation.
Industry context: Manufacturers operate under OSHA + ISO 9001 + sector-specific quality regimes. AI-native delivery onto factory floors must respect MES integration, deterministic safety bounds, and human-in-the-loop for any actuator command.
Benchmarks we hit
Reference benchmarks from production deployments of field service in manufacturing-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
CSAT (post-interaction) Lift requires escalation paths kept obvious and fast | 4.1 / 5 | 4.4 / 5 | +0.3 |
Agent attrition / quarter Agents handle higher-judgment cases; AI absorbs the repetitive volume that drove burnout | 11% | 5% | −55% |
Time-to-value for new customer Personalized onboarding paths assembled from customer signal + product graph | 18 days | 4 days | −78% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
When manufacturing leaders ask how we run field service differently from a typical consulting engagement, the honest answer is: we never stop running it. The Build phase produces the workflow, but the operating model — weekly reviews, edge-case folding, calibration drift detection — is what compounds value. Without it, AI accuracy degrades silently within months.
What we build inside the workflow
For manufacturing workflows, the design choice that matters most is where to draw the boundary between automation and human judgment. On field service, we draw three lines: full automation (high-confidence, low-stakes, reversible actions), assisted review (drafts with reviewer one-click approval), full human ownership (policy edits, escalations, exceptions). The lines are documented, instrumented, and revisited quarterly as confidence calibration improves.
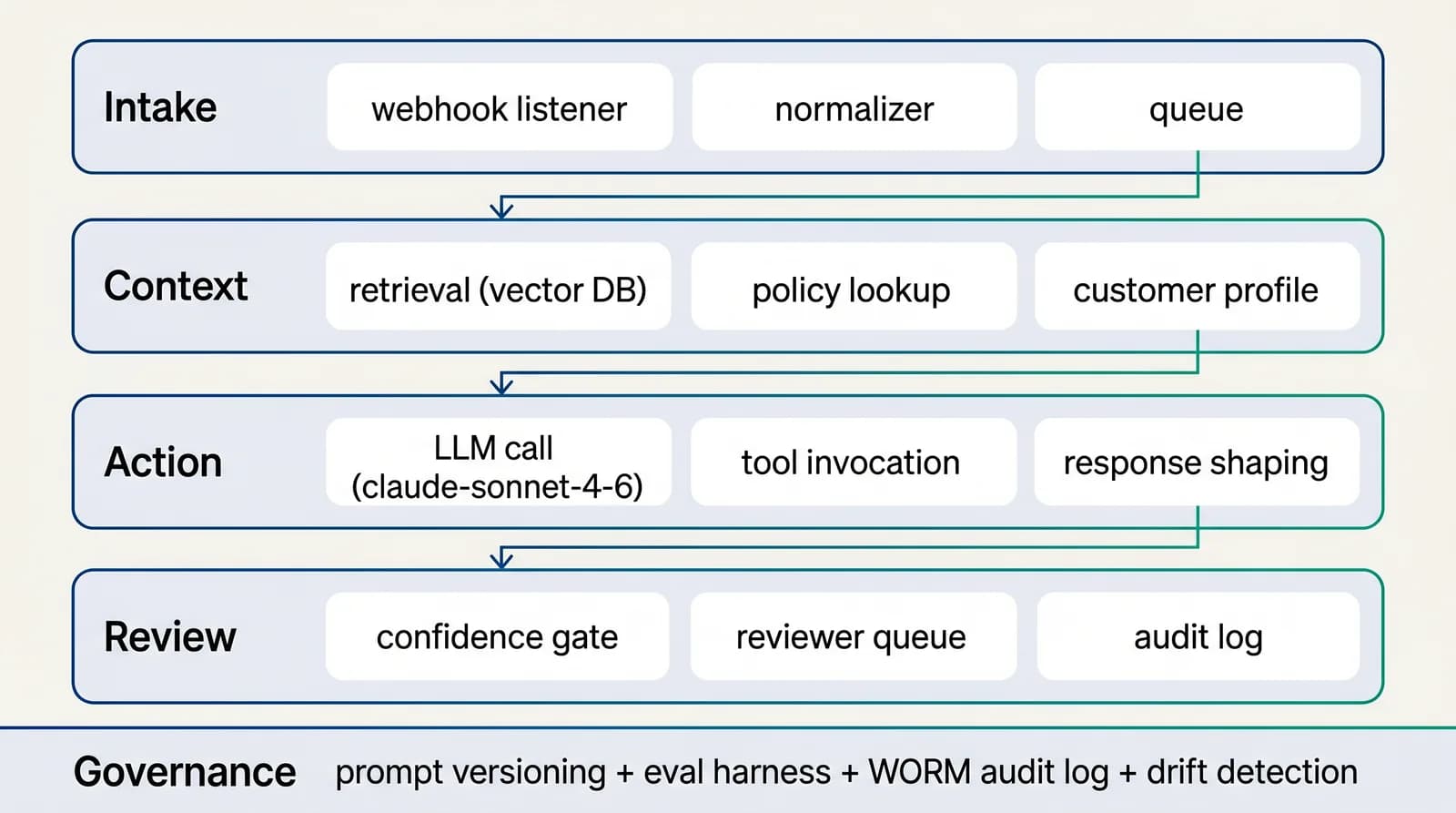
Reference architecture
4-layer AI-native workflow for customer experience
Four layers, in the order data flows through them: intake (classify and tag), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases). Each layer is independently observable.See the full architecture diagram for Customer Experience →
AI-native vs traditional approach
Side-by-side comparison of an AI-native engagement against the alternatives most manufacturing teams evaluate for field service: time to production, pricing model, governance posture, operator throughput, unit cost, exit path.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Lead time to live deployment | 6-12 months | 6-10 weeks (thin slice) |
| Engagement billing | Time-and-materials or annual contract | Phased fixed-price (Discovery → Build → opt Run) |
| Audit posture | Manual logs, periodic review | Versioned prompts, audit logs, reviewer queues, attestations |
| Per-operator capacity | 1.0× (baseline) | −55% |
| Per-case cost | Industry baseline | Sub-dollar marginal cost on routine envelope |
| Exit path | Knowledge transfer takes 6+ months | Documented exit at every phase; artefacts in your repo |
Traditional quality inspection costs $4-9 per unit at scale; AI-native vision-based inspection compresses to $0.20-0.80 with reviewer queue on low-confidence detections.
Engagement scope & pricing
Field Service delivery is structured as Discovery → Build → opt-in Run, each priced and scoped independently. No multi-quarter retainer commitments.
CX engagement
Three commercial envelopes, three deliverables. The next phase is scoped against the evidence the prior phase produced.
Phase 1 · Discovery
$5k
2-week sprint
Phase 2 · Build
$18k–$25k
6-9 weeks
Phase 3 · Run
$2k–$3k / mo
optional, hourly bank also available
~$28k–$48k typical year 1 (60% take the run option for ~6 months)
Customer journey design, escalation handling, tone calibration, and CX KPI reporting.
Start with Discovery; nothing more is required to begin. Build is scoped from the Discovery output. Run, if it happens, is month-to-month with no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Workflow mapping, integration scoping, baseline capture, risk register, labelled-test-set seed. The output is the Build SoW with a fixed price and named deliverables.
Phase 2 · Weeks 2–4
Design
Two weeks of design produces the technical artefacts Build executes against: the workflow blueprint, the data-access plan, the prompt strategy, the review-queue UX, the audit-log shape, the dashboard wireframes.
Phase 3 · Weeks 4–8
Build
We ship a production thin slice on real data, with versioned prompts, evaluation harness, and human review.
Phase 4 · Weeks 8+
Run
Optional Run phase, month-to-month, no lock-in. Weekly performance review against the Discovery baseline. Quarterly architecture retrospective. The cadence is documented; your team can absorb it any time.
Interactive ROI calculator
Estimate your AI-native ROI for field service
Reference inputs below are typical for manufacturing teams in the customer experience cluster. Adjust them to match your situation.
Projected
Current monthly cost
$42,000
AI-native monthly cost
$13,000
Annual savings
$348,000
69% cost reduction · ~920 operator-hours freed / month
Governance and risk controls
Internal auditors and external regulators in manufacturing converge on the same three questions: data provenance, decision traceability, replayability. Our control stack answers all three from the same audit log — one source of truth, queryable, exportable, signed. No spreadsheet reconciliation, no after-the-fact narrative.
How we report ROI
The business case lives in operating metrics, not model benchmarks. For field service, the metrics that matter are first time fix rate, travel time, SLA attainment, and service margin. For Manufacturing, leadership will also care about OEE, scrap rate, quote cycle time, on-time delivery, and cost of quality. Every build decision we make connects to one of those metrics, and we publish a weekly performance review during the Run phase.
Selected portfolio
Real builds — field service in manufacturing and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with field service in manufacturing or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q2 2026
Internal staff portal — multi-association operations in role-based dashboards
Mid-market property operator · GCC region
Role-scoped portal for property managers, accountants, and maintenance staff. Reuses the OA data model from the management SaaS (zero duplication), adds multi-association switching, maintenance ticket lifecycle, financial reporting, and document storage tied to each association workspace.
- Next.js + tRPC
- NextAuth role-based access
- Drizzle ORM shared schema
Q3 2025
On-demand regional aviation booking — flexible flight network across smaller cities
Regional aviation operator · DACH
Booking and operations stack for an on-demand regional aviation network connecting secondary cities. Customer-facing booking flow with dynamic availability, operator-side dispatch tools, route economics dashboards. Designed for a sustainable flight-network operating model rather than fixed-schedule airline patterns.
- Next.js + native-app companion
- Dynamic availability engine
- Operator dispatch console
Q2 2026
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual
Mid-market property operator · GCC region
Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one.
- Next.js + tRPC
- Per-unit auth + audit trail
- Bilingual EN/AR (next-intl)
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native field service engagements in manufacturing contexts.
Escalation invisible
Customer trapped in AI loop with no obvious 'talk to human' path; CSAT crashes
Escalation surface designed before automation; 'human now' button on every screen + voice escalation
What the field reality means for the architecture
The signal that matters most in manufacturing operations is the gap between the schedule and the actual. The dashboard tells you what was planned; the field tells you what happened; the variance is where the operating leverage lives. AI-native delivery is at its best when the workflow surfaces that variance early, attributes it to the right cause class, and routes corrective action to the right owner — before the next scheduling cycle commits the same assumption.
Week-by-week shape of the Build phase
Week 1 — Discovery handover and labelled test set capture. We sit with the operator team running field service today, watch a working day end to end, and capture 200+ real cases as the labelled test set. By Friday we have the workflow map, the system inventory (ERP, MES, and adjacent), the risk register, and the success metrics aligned with your KPI of first time fix rate.
Week 2 — Architecture and integration scoping. We design the four-layer workflow (intake, context, action, review), confirm the retrieval shape, lock the prompt strategy direction, and produce the integration plan against ERP. The output is the Build statement of work with a fixed price and a named deliverable per phase.
Week 3-4 — Build sprint 1: retrieval and intake. We stand up the retrieval index against your approved sources, build the intake classifier, instrument the audit log, and run the first eval cycle against the labelled test set. The thin slice is functional but not production-deployed.
Week 5-6 — Build sprint 2: action and review. We ship the action layer, build the reviewer queue UI, calibrate the confidence thresholds against the labelled test set, and onboard the first reviewer cohort. By end of week 6 the workflow is processing low-stakes production traffic with full audit logging.
The rest of the Build phase widens the production envelope case-by-case based on the reviewer feedback loop. By the end of Build, field service for manufacturing is running on real traffic with the operating cadence already established.
The Build phase rhythm for field service in manufacturing is engineered for the bottleneck most teams hit at the end of week 2: ambition outrunning evidence. We engineer for the opposite — evidence first, ambition calibrated to it.
Week 1 produces the discovery report, the labelled test set, the integration plan, the risk register, the success metrics. Week 2 stands up the retrieval index, the intake classifier, the eval harness, the audit log. Week 3 wires the action layer with reviewer approval, runs the first three eval cycles, produces the first calibration report. Week 4 ships the thin slice to a narrow production audience (5-10% of routine cases), instruments the operator feedback loop, and runs the first weekly review.
By day 30, the dashboard is live, the system is processing real manufacturing cases, the operator team is engaging with the reviewer queue, the eval harness is gated on every change, and the next two weeks of Build are scoped from concrete evidence rather than initial assumptions. Days 31-45 widen the production envelope to 40-60% of routine cases. Days 46-60 absorb the remaining routine envelope and start handling the first tranche of exceptional cases. By the close of Build (day 60-70), the workflow is operating at its target envelope with the calibration discipline in place to handle drift, edge cases, and future model changes.
A working example of this pattern
The closest pattern reference we ship for field service in manufacturing is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Internal staff portal — multi-association operations in role-based dashboards. Role-scoped portal for property managers, accountants, and maintenance staff. Reuses the OA data model from the management SaaS (zero duplication), adds multi-association switching, maintenance ticket lifecycle, financial reporting, and document storage tied to each association workspace. (Mid-market property operator · GCC region, Q2 2026.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to manufacturing (ERP and the adjacent systems) and the prompt strategy tuned to the field service vernacular in your category.
For US buyers
US compliance scaffolding for field service in manufacturing (NIST AI RMF)
Manufacturing engagements touching US clients on field service ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for manufacturing is NIST AI Risk Management Framework (AI 100-1) (NIST AI RMF) — addressed below alongside the adjacent frames we encounter.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
Premium engagement page · hand-edited
The bespoke playbook for this combination
Field-service dispatch, predictive maintenance, parts forecasting — bridging the data-physical gap.
Architecture, end-to-end
AI workflow for manufacturing field-service teams: dispatch optimisation, predictive maintenance from sensor + maintenance-history data, parts forecasting, technician-time copilot.
Sensor + maintenance-history ingest (ServiceMax / IFS / Salesforce Field Service) → predictive maintenance classifier → dispatch optimiser balancing technician skills, geography, parts availability → technician mobile copilot for diagnostic guidance (offline-capable) → audit log for warranty and SLA review.
Specific risks we engineer against
The four to six failure modes we have actually encountered on engagements that look like yours. Each has a documented mitigation in the Build SOW.
RiskFalse positive maintenance prediction triggers unnecessary truck roll
MitigationConfidence-thresholded dispatch; manual review on high-cost truck rolls; precision/recall tracked weekly.
RiskField technician rejects the diagnostic assistant
MitigationCo-designed with 5 senior technicians during Build; adoption tracked; refinement loop weekly.
RiskSensor data quality varies across equipment generations
MitigationPer-equipment-class confidence calibration; data quality flags in the dispatch view.
Reference deltas on manufacturing field-service engagements
| Metric | Before | After | Window |
|---|---|---|---|
| First-time-fix rate | 62–72% | 82–90% | 90 days |
| Unplanned downtime / asset / month | 12–18 hours | 5–8 hours | 120 days |
| Truck rolls / month | Baseline | −18 to −28% | 90 days |
| Parts stockout incidents | Baseline | −40 to −55% | 120 days |
Reference from discrete and process manufacturers running field service at $100M–$1B revenue band.
Objections we hear most often
Will my technicians actually use a mobile app in the field?+
We co-design the mobile UX with 5 senior technicians during Build, offline-first, voice-input where keys are dirty. Adoption tracked.
What if sensor data is sparse?+
Per-equipment-class models with confidence bands. The workflow surfaces what it knows and flags what it doesn't.
Mini SOW
What the Build SOW looks like
Total fee
$26,000 Discovery + Build
Duration
10 weeks to thin-slice production
Week 1–2
Discovery: equipment classes mapped, sensor data audited, technician shadowing.
Week 3–5
Predictive maintenance classifier; dispatch optimiser.
Week 6–8
Technician mobile copilot in pilot region; 100% review.
Week 9–10
Production rollout; KPI dashboard live.
Procurement FAQ
Do you connect to ServiceMax / IFS?+
Yes, via standard APIs. Integration scoped in Discovery.
Where is operational data stored?+
In your cloud region. Field-edge data syncs to central layer on connectivity.
Real shipped systems
What our clients say
Below: attributions from active clients. Client identities are withheld in public form pending written approval; live references available to qualified procurement contacts on discovery call.
AI SaaS · DACH region
“They shipped the production version of our pricing brain in 6 weeks, including the billing layer and the onboarding flow. We had been bouncing between contractors for 4 months before.”
Founder, AI Pricing SaaS
Outcome: From 0 to live SaaS with paying customers in 6 weeks. Production billing live, AI onboarding flow shipped, 2 pricing tiers active.
Government-licensed legal services platform · GCC region
“A complete bilingual platform compliant with regulator requirements. Technical quality and delivery speed are outstanding.”
Founding team, regulated legal marketplace
Outcome: Ministry-of-Justice-licensed national legal marketplace, EN/AR bilingual, in 16 weeks. Directory + bookings + legal tools + emergency contacts.
Property management operator · GCC region
“We replaced spreadsheets and 4 disconnected tools with a single OA platform. 55 screens, 47 tables, a voting platform, and an internal portal — all on the same identity layer.”
CTO, multi-region property operator
Outcome: Centralised property operations across multiple owners associations. 14-week first release; 8-week follow-on for the staff portal; 6-week follow-on for e-voting.
Before / after
Concrete deltas from shipped engagements
Owners-association management workflows
Property management operator · GCC
Operator was scaling association count and could not maintain manual coordination. Replaced 4 fragmented tools with a single AI-augmented operational backbone.
Metric
Operational surface area
Before
Fragmented across spreadsheets + email + 4 SaaS tools
After (14 weeks Build phase)
Unified SaaS with 55 screens / 47 normalized tables / cross-app identity
Pricing strategy SaaS onboarding
AI pricing SaaS · DACH
Founder shipping AI-native pricing platform for early-stage SaaS. Discovery + Build delivered a working SaaS with subscription billing and an AI brain that learns from each customer.
Metric
Time-to-pricing for a new founder
Before
3–4 weeks of consultant time + spreadsheets
After (6 weeks total Build)
9-step structured AI workflow, completed in 30–45 minutes
Lawyer discovery and appointment booking
National legal marketplace · GCC
Regulated entity needed to launch the national reference platform for legal services. Delivered a Next.js 16 monorepo with bilingual content layer, PDF generation, and police directory.
Metric
Citizen access to certified legal services
Before
Fragmented across social media, no central directory, phone-only booking
After (16 weeks Discovery + Build)
Ministry-licensed bilingual EN/AR marketplace; multi-channel booking; legal tools; emergency hotline
Marketing site + booking funnel
Premium vehicle care specialist · DACH
Niche detailing workshop needed to project premium positioning matching their workmanship. AI-assisted copywriting + image art-direction compressed launch time.
Metric
Brand perception alignment
Before
Generic web presence — did not match workmanship quality
After (3 weeks concept-to-live (AI-augmented build))
Premium responsive site, German-market SEO foundation, appointment-oriented CTAs
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
Manufacturing teams that build successfully in-house tend to have an existing ML platform, a labelled data culture, and a product manager dedicated to the workflow. If any of those is missing, the project tends to stall at proof-of-concept. We replace those three dependencies with a scoped engagement and a senior delivery team.
What to ask us before signing
- Ask for a 30/60/90-day plan with named deliverables, not a vague phase description.
- Ask how we handle the long tail of edge cases the operator team has never encoded — escalation, calibration, capture.
- Ask for the model and provider strategy — single-model, multi-model, fallback paths, cost forecasting.
- Ask how the reviewer queue UX is designed and whether your operator team can shape it during Build.
- Ask for references from manufacturing-adjacent engagements — sector, scope, and outcome dimensions.
Recommended first project
Pick the field service flow that has three properties: high enough weekly volume to produce a labelled test set quickly, structured enough to evaluate, and reversible if a decision is wrong. That is the wedge that ships fast, proves adoption, and earns the credibility to extend into the harder cases. The first 30 days are spent on the labelled test set, the integration to ERP, and the thin-slice workflow. The next 60 days are spent operating the thin slice on real manufacturing traffic, widening the automation envelope week by week. By day 90 you have an empirical track record, not a vendor's projection, and the next workflow can be scoped against that evidence.
Frequently asked questions
How do you automate field service in manufacturing with AI?+
We map the existing field service workflow inside manufacturing, identify the high-volume, high-structure tasks, and build an AI agent that handles those tasks while routing low-confidence cases to a human reviewer. The build connects to your ERP, MES, QMS, runs against a labelled test set, and ships behind a reviewer queue before it sees production traffic. We then operate it, measure first time fix rate, travel time, SLA attainment, and service margin, and improve it weekly.
What does it cost to automate field service for manufacturing teams?+
~$28k–$48k typical year 1 (60% take the run option for ~6 months). The structure: $5k Discovery (2-week sprint) → $18k–$25k Build (6-9 weeks) → optional $2k–$3k / mo Run. Customer journey design, escalation handling, tone calibration, and CX KPI reporting.
What is the best AI agent for field service in manufacturing?+
Model selection on field service for manufacturing happens against five criteria: quality on your labelled test set, cost per inference at your projected volume, latency budget for the user-facing path, provider reliability over 12-18 months, contractual data-handling posture. We bring the comparative methodology from prior engagements and run it during Build; the winning model is the one that survives all five, not the one that wins the demo.
How long does it take to deploy AI field service for manufacturing?+
A thin-slice deployment in 2-week sprint after Discovery, with real manufacturing data and real reviewers. The full Build phase runs 6-9 weeks. By day 90, first time fix rate, travel time, SLA attainment, and service margin is instrumented, the team has a baseline, and leadership has the data needed to decide on expansion into adjacent manufacturing workflows.
What do we own, and what do you own?+
What we ship as code lives in your repository under your IAM. The prompts, the evaluation harness, the integration code, the reviewer UI, the infrastructure-as-code — all in your Git, not in our SaaS. We bring the engineering, the operating discipline, and the cadence; you bring the data, the policy, and the operator team. The handover is documented from day one of Build, not deferred to the end.
How is the escalation surface designed?+
The path from automation to human is one click, with the customer's context preserved across the handoff. The reviewer queue surfaces low-confidence cases with the supporting evidence pre-assembled so the operator's time goes to judgment, not context-gathering. We track escalation rate as a first-class metric — a falling rate signals genuine learning; a rising rate signals drift.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
first time fix rate, travel time, SLA attainment, and service margin measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with ERP and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on manufacturing engagements. Cited here so you can verify and dig deeper.
- NIST Manufacturing Extension Partnership
- AI Adoption Statistics — U.S. Bureau of Labor Statistics
- AI Risk Management Framework (AI RMF 1.0) — NIST
- State of the Connected Customer — Salesforce Research
- Customer Service & AI — Zendesk CX Trends
- MAPI Industrial AI Manufacturers Report — Manufacturers Alliance
- World Manufacturing Report — AI Edition — World Manufacturing Foundation
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Manufacturing engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.