Financial Services · Knowledge & Insight
Automate Knowledge Management in Banking with AI
We design, build, and run AI-native knowledge management for bank executives, retail banking leaders, risk teams, and digital transformation owners. This page describes the engagement: scope, pricing, timeline, controls, and the KPIs we commit to.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native knowledge management for banking — Production knowledge management for banking delivered in vertical slices, each gated by the labelled test set captured during Discovery, each handing operational ownership progressively to your team. Expected delta on search success: −87%.
Key facts
- Industry
- Banking
- Use case
- Knowledge Management
- Intent cluster
- Knowledge & Insight
- Primary KPI
- search success, time saved, knowledge freshness, and repeated question reduction
- Top benchmark
- Knowledge freshness (median age cited): 94 days → 12 days (−87%)
- Systems integrated
- core banking, CRM, KYC platforms
- Buyer
- bank executives, retail banking leaders, risk teams, and digital transformation owners
- Risk lens
- model risk, explainability, consumer protection, fraud, privacy, and regulatory reporting
- Engagement timeline
- Discovery 2.5 weeks → Build 7 weeks → Run continuous
- Team size
- 2 senior delivery (1 architect + 1 implementer)
- Discovery price
- $6k · 2-week sprint
- Build price
- $22k–$30k · 7-10 weeks
Primary outcome
make institutional knowledge searchable and actionable
What we ship
knowledge graph, retrieval assistant, content governance, and freshness workflow
KPIs we report on
search success, time saved, knowledge freshness, and repeated question reduction
Why Banking teams hire us for this
Banking leaders rarely need another AI pilot. They need a workflow that survives quarterly review, that an auditor can inspect, and that a new hire can be onboarded into. Our engagement model is built around that bar — knowledge management is shipped as a system, not as a demo, and the operating cadence is part of the deliverable from week one.
Microsoft's Work Trend Index data shows that knowledge workers in banking spend up to 30% of the week searching for or recreating information that already exists internally. Source-grounded retrieval is the highest-leverage AI use case in this segment.
Industry context: Banks operate under SR 11-7 model risk management (US Fed), CRR3 (EU), and rising AI-specific guidance (EBA, OCC). Every model decision needs replayable audit trail with versioned prompts, model card, and named human owner for high-impact actions.
Benchmarks we hit
Reference benchmarks from production deployments of knowledge management in banking-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Knowledge freshness (median age cited) Auto-refresh of approved sources + freshness scoring on retrieval | 94 days | 12 days | −87% |
Repeated-question volume AI surfaces existing answers + flags content gaps for SME refresh | 100% (baseline) | 44% | −56% |
Decision cycle time Insight assembly compressed from manual deck-building to instrumented dashboard | 9 days | 1.5 days | −83% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
A traditional agency sells people, hours, and deliverables. We sell a designed outcome. For knowledge management, the operating model includes intake, data access, prompt and retrieval architecture, workflow orchestration, evaluation, human review, reporting, and continuous improvement. The human role stays central: own source authority, approve sensitive answers, maintain taxonomy, and retire stale content. In banking, where the risk lens covers model risk, explainability, consumer protection, fraud, privacy, and regulatory reporting, that separation matters.
What we build inside the workflow
A strong implementation starts with a clear inventory of the current work. For Banking, that means understanding how data moves through core banking, CRM, KYC platforms, fraud systems, data warehouses, who owns each decision, and where handoffs slow the team down. We document current cycle time, error rates, quality review steps, rework, and the volume of requests or records flowing through the process. The automation layer will indexes documents, detects duplicates, answers questions with citations, and recommends updates.
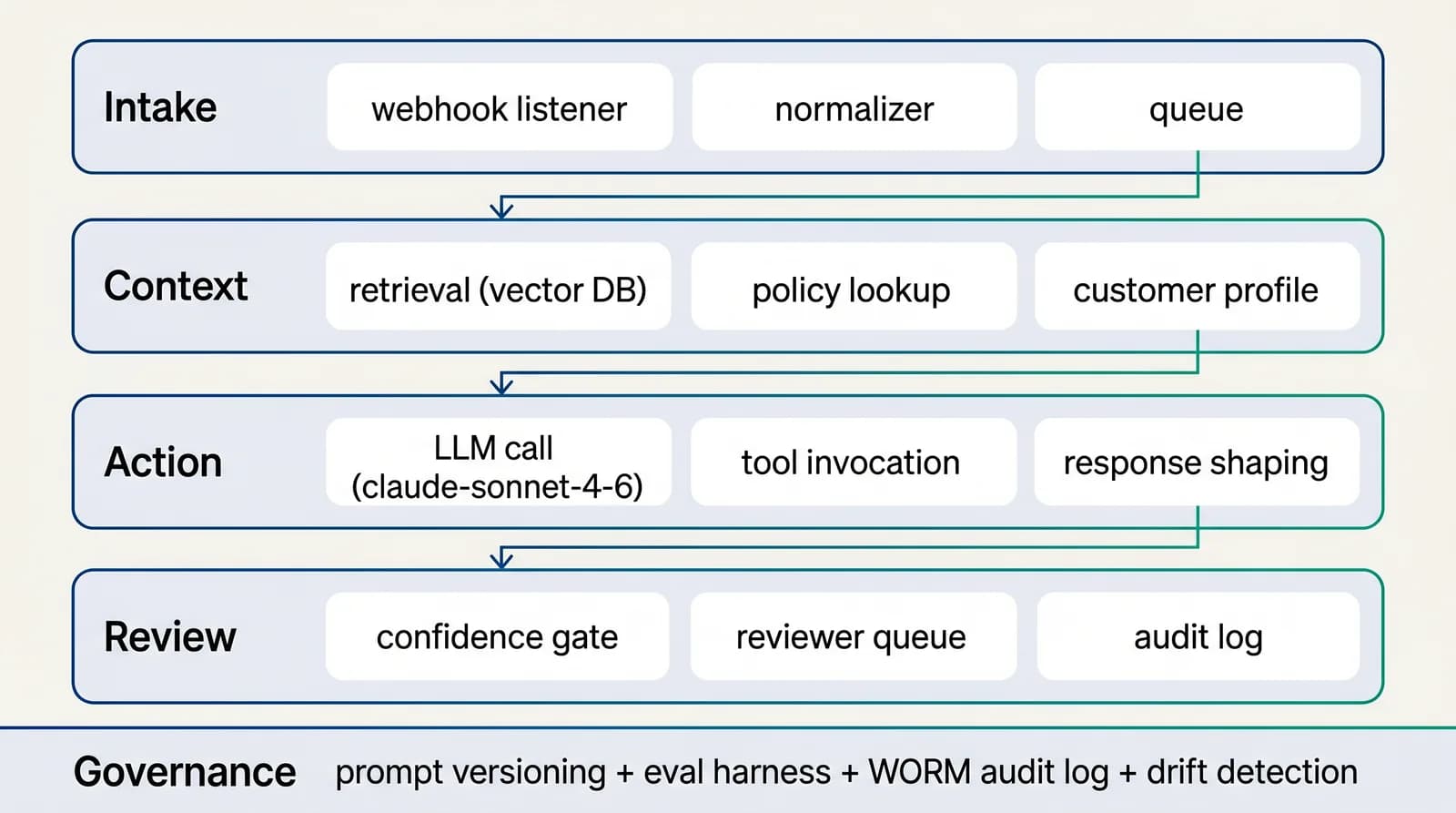
Reference architecture
4-layer AI-native workflow for knowledge & insight
Four layers, in the order data flows through them: intake (classify and tag), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases). Each layer is independently observable.See the full architecture diagram for Knowledge & Insight →
AI-native vs traditional approach
What changes between a traditional knowledge management program in banking and an AI-native engagement is not the goal — it is the architecture, the operating cadence, and the exit posture. The table below makes the differences explicit.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Time to production | Two quarters minimum | Production traffic within 6-10 weeks |
| Pricing model | FTE hourly retainer or fixed staffing | Three independent commercial envelopes |
| Audit / governance | Document-driven, periodic snapshot | Runtime guardrails + audit log + governance map + quarterly attestation |
| Operator throughput lift | 1.0× (baseline) | −56% |
| Cost per unit | Linear with operator headcount | Typically 60-80% lower |
| End-of-engagement | Multi-quarter notice + knowledge loss | Month-to-month Run, full handover plan in Build SoW |
Traditional vendor KYC costs $8-14 per onboarded account; AI-native KYC with grounded source check + reviewer queue brings it to $1.20-2.80, audit-ready for OCC examination.
Engagement scope & pricing
Three phases, three commercial envelopes. Discovery is the only commitment to start; Build and Run are scoped against the Discovery output.
Insight engagement
Each phase is independently committable. Discovery is the only one you have to start with.
Phase 1 · Discovery
$6k
2-week sprint
Phase 2 · Build
$22k–$30k
7-10 weeks
Phase 3 · Run
$3k–$5k / mo
optional, hourly bank also available
~$34k–$60k typical year 1 (60% take the run option for ~6 months)
Source curation, retrieval architecture, evaluation harness, and decision dashboards.
Start with Discovery; nothing more is required to begin. Build is scoped from the Discovery output. Run, if it happens, is month-to-month with no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Workflow mapping, integration scoping, baseline capture, risk register, labelled-test-set seed. The output is the Build SoW with a fixed price and named deliverables.
Phase 2 · Weeks 2–4
Design
Design phase is where the irreversible architectural choices are made: layer boundaries, substitution interfaces, governance posture, evaluation methodology. We invest disproportionately here because corrections in Build are 10× more expensive.
Phase 3 · Weeks 4–8
Build
We ship a production thin slice on real data, with versioned prompts, evaluation harness, and human review.
Phase 4 · Weeks 8+
Run
Monthly month-to-month Run cadence: Monday metric review, Wednesday prompt and retrieval refresh, Friday calibration audit. The cadence is the deliverable; the prompts are the artefacts that change between cadence cycles.
Interactive ROI calculator
Estimate your AI-native ROI for knowledge management
Reference inputs below are typical for banking teams in the knowledge insight cluster. Adjust them to match your situation.
Projected
Current monthly cost
$26,400
AI-native monthly cost
$6,684
Annual savings
$236,592
75% cost reduction · ~1,672 operator-hours freed / month
Governance and risk controls
Risk in banking comes from three failure modes: the model is wrong, the source data is wrong, or the workflow allows the wrong action. We design for each mode separately — evaluation harness for model error, source curation and freshness for data error, allow-listed tool calls and approval queues for action error. Each has a defined owner and a measurable SLA.
How we report ROI
ROI on knowledge management shows up in two timeframes for banking: immediate (cycle time, throughput, error rate — visible within 30 days of Run) and structural (operating model maturity, knowledge capture, team capacity unlock — visible at 6-12 months). The first justifies the engagement; the second is what changes the business.
Selected portfolio
Real builds — knowledge management in banking and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with knowledge management in banking or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q4 2025
Internal automation tool — workflow automation for consulting operations
Multi-vertical consulting group · Europe
Internal automation tool to streamline workflows, reduce manual administrative load, and improve operational efficiency across consulting and management processes. Integrates with existing systems rather than replacing them, automating handoffs and document flows that previously moved through email.
- Workflow automation engine
- Document-flow integration
- Operational dashboards
Q3 2025
Radiology workflow application — case handling and reporting
Medical imaging operator · Europe
Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access.
- Web app + secure storage
- Structured reporting
- Audit-trail compliance
Q1 2026
Premium bilingual corporate site + internal CRM
Multi-vertical consulting group · Europe
Corporate marketing site with animated bento-grid editorial, bilingual content architecture, and an internal CRM behind the scenes for lead handling. Designed to project a premium positioning aligned with enterprise buyers while keeping marketing-team ownership of the content layer.
- Next.js + animated bento grids
- Bilingual content layer
- Internal CRM integration
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native knowledge management engagements in banking contexts.
Long-context dumping vs hybrid retrieval
Engineering shoves 200k tokens of corpus into context, accuracy plateaus
Hybrid retrieval (BM25 + embeddings + reranker) + targeted chunks; eval harness benchmarks both approaches
Regulatory landscape and how we ship inside it
Three regulatory pressures shape every banking engagement we run on knowledge management. The first is explainability — the regulator's right to receive a coherent rationale for any decision the workflow produced, in language a senior examiner understands. The second is replayability — the ability to reconstruct the inputs, model versions, and reasoning chain that led to that decision, six months or two years later. The third is segregation of duties — the line between automated action, drafted-with-review, and reserved-to-human steps, with no operator able to silently widen the automation envelope.
We address all three at the architecture level rather than as policy overlays. Explainability is wired into the prompt pipeline: every customer-facing output ships with the supporting source citations, the confidence band, and the policy clauses the model applied. Replayability is wired into the audit log: every inference call is stored with its full input context, model fingerprint, retrieval bundle, and downstream effects, with a retention policy aligned to the regulator's longest plausible review window. Segregation is wired into the reviewer UI: each step has a typed permission, each escalation has a named owner, each policy-edit action requires a second pair of eyes from a different team.
The practical effect for banking leadership is that examinations stop feeling like archaeological digs. The supervisory question — "show me how this decision was made on date X" — becomes a one-query lookup in the audit log, returning the policy clauses, the source citations, the model version, the reviewer trail, and the downstream actions. The traditional posture would assemble that record over weeks; the AI-native posture assembles it on demand. That is the operational difference between a controlled AI workflow and a research prototype dressed in compliance language.
Data residency and sovereignty constraints in banking are easier to honor when designed into the architecture than when bolted on later. The retrieval index lives in your cloud region; the model provider is selected to align with your data-residency expectations; the audit log retention follows your jurisdiction's longest plausible review window. These are Discovery-phase decisions, not late-Build pivots, because reversing them costs months.
The tactical playbook for the first 30 days
Our Build cadence on knowledge management for banking is bias-corrected against the two failure modes we have seen kill banking AI projects most often: scoping that drifts week-by-week, and a labelled test set that arrives in week 6 instead of week 1.
We fix the scoping by signing the Build statement of work before any code is written — the deliverables are named, the integration footprint is bounded, the milestones have dates. We fix the labelled test set timing by treating it as the week-1 deliverable. Week 1 is not "scoping week" — it is "labelled-test-set week", because every subsequent engineering decision is measured against that test set.
Week 2: retrieval index live with first batch of approved sources. Week 3: intake classifier scoring against the test set, first calibration report. Week 4: action layer drafting with reviewer approval; first end-to-end case flow. Week 5-6: thin slice in production on 5-15% of routine banking traffic, first weekly review with the operator team. Weeks 7-10: production envelope widens case-class by case-class, calibration loop tunes against the empirical evidence, exceptional cases route to enriched escalation. By day 60-70, the workflow is operating at its target envelope.
How this rhymes with a recent build
The closest pattern reference we ship for knowledge management in banking is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Radiology workflow application — case handling and reporting. Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access. (Medical imaging operator · Europe, Q3 2025.)
The reason that engagement is a useful reference is not the surface match — it is the underlying decision structure. The same questions show up on knowledge management for banking: where to draw the automation boundary, how to calibrate confidence thresholds against the labelled test set, what to put in the reviewer UI, how to instrument drift. The answers transfer; the implementation specifics adapt to your stack.
For US buyers
US compliance scaffolding for knowledge management in banking (FINRA, SEC, GLBA)
Banking engagements touching US clients on knowledge management ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for banking is Financial Industry Regulatory Authority (FINRA) — addressed below alongside the adjacent frames we encounter.
FINRA
Financial Industry Regulatory Authority
Authority: FINRA (self-regulatory organisation under SEC oversight)
- Scope
- Broker-dealer supervision, communications with public, recordkeeping (Rule 4511), supervision (Rule 3110), AML.
- How we ship inside it
- Communications generated or assisted by AI workflows are captured under FINRA Rule 4511 retention (minimum 3 years, 6 years for some categories). Supervisory review queues are designed for FINRA Rule 3110 supervisory documentation. We do not provide investment advice; the workflow surfaces evidence for human approval.
SEC
Securities and Exchange Commission
Authority: U.S. Securities and Exchange Commission
- Scope
- Investment adviser oversight, market integrity, registrant communications, AI/algorithmic disclosure (e.g., proposed conflicts-of-interest rule).
- How we ship inside it
- Investment-adviser engagements include disclosure templates aligned with SEC proposed conflicts-of-interest framework for predictive data analytics. AI-generated outputs touching investor decisions are flagged for adviser sign-off.
GLBA
Gramm-Leach-Bliley Act
Authority: FTC / federal banking regulators
- Scope
- Safeguarding non-public personal financial information (NPI), privacy notice, security programme requirements.
- How we ship inside it
- Engagements touching NPI follow GLBA Safeguards Rule: written information security programme, designated qualified individual, access controls, monitoring. NPI flows through encrypted channels only. Subprocessor agreements include GLBA flow-down clauses.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
Premium engagement page · hand-edited
The bespoke playbook for this combination
Grounded knowledge retrieval over approved bank sources — policies, credit and product manuals, desk procedures, regulatory interpretations — with source-of-record citations, information-barrier enforcement, and human review on consequential answers.
Architecture, end-to-end
Knowledge management AI for banks and broker-dealers. RAG over your approved internal sources of record — policy and procedure libraries, credit and product manuals, SOPs and desk procedures, regulatory interpretations — so relationship managers, analysts, and operations staff get cited answers instead of guesses. Every answer carries provenance back to the source document and version; information barriers (Chinese walls) and MNPI segregation are enforced at the retrieval layer; access is logged and surveilled; consequential answers route to a reviewer queue.
Four layers ship in Build. (1) Intake: connectors to your approved sources of record only — policy/procedure management system (e.g. NICE Actimize policy store, ServiceNow, SharePoint/Confluence), credit and product manuals, desk procedures, the firm's logged regulatory-interpretation library — each document carrying an effective-date and supersession status. (2) Context: a retrieval index partitioned by information barrier and entitlement; MNPI-bearing material (deal data, watch/restricted lists) lives in segregated partitions that public-side users cannot retrieve, mirroring your existing wall-crossing model; only current, non-superseded versions are retrievable by default. (3) Action: a Claude-class model answers questions with mandatory citation to the source-of-record document and version, refuses when grounding is absent, and routes consequential answers (anything a user would act on — credit policy, suitability, regulatory interpretation) to a reviewer. (4) Review + surveillance: SME/supervisor reviewer queue with one-click approve / correct / escalate; every query, retrieved document, citation, and disposition writes to a tamper-evident audit log retained per FINRA Rule 4511 (3–6 years by record category) and surveilled alongside your existing communications surveillance. Model documentation aligns with SR 11-7 expectations: model card, validation evidence on a labelled question set, ongoing monitoring, named accountable individual.
Specific risks we engineer against
The four to six failure modes we have actually encountered on engagements that look like yours. Each has a documented mitigation in the Build SOW.
RiskMNPI leaks across an information barrier (public-side user retrieves private-side material)
MitigationRetrieval is partitioned by information barrier and entitlement, mirroring your wall-crossing model; MNPI-bearing partitions (deal data, watch/restricted lists) are unreachable from public-side identities by design; every cross-partition attempt is logged and surveilled. Wall configuration is co-signed by Compliance during Build.
RiskA stale or superseded policy is surfaced and acted on as if current
MitigationEvery document carries effective-date and supersession status; only current, non-superseded versions are retrievable by default; answers cite the version and effective-date inline; superseded content is quarantined from default retrieval and a freshness audit runs weekly.
RiskThe model fabricates regulatory guidance or a policy position that does not exist
MitigationCitation to an indexed source-of-record is mandatory for every claim; ungrounded questions are refused, not answered; consequential answers (credit policy, suitability, regulatory interpretation) route to an SME reviewer before the user relies on them. Interpretation stays human-owned.
RiskRecordkeeping or audit gap under FINRA Rule 4511 / SEC / GLBA examination
MitigationEvery query, retrieved document, citation, reviewer disposition, and entitlement decision writes to a tamper-evident audit log with cryptographic chaining, retained 3–6 years per record category; examination evidence export is a single command and is reviewed quarterly with Compliance.
RiskEntitlement creep — users accumulate access to knowledge partitions beyond their need
MitigationEntitlements inherit from your IAM/SSO roles, not a parallel grant system; access is least-privilege by default, reviewed on a recertification cadence, and every grant/retrieval is logged; orphaned or over-broad entitlements surface in the quarterly access audit.
Reference deltas on bank knowledge-management engagements
| Metric | Before | After | Window |
|---|---|---|---|
| Time to find the current, authoritative policy answer | 15–40 min | 1–3 min | 30 days |
| RM / analyst onboarding ramp to productivity | 3–5 months | 6–9 weeks | first new cohort |
| Knowledge-reuse rate (answers grounded in existing SOPs vs. re-asked of SMEs) | Sparse / tribal | 60–75% self-served | 90 days |
| Audit / exam-prep time for knowledge and procedure evidence | 40–80 hours | Auto-generated pack + 4–8 hours review | first cycle |
| Share of answers delivered with a verified source-of-record citation | Not tracked | 98–100% | 60 days |
Reference ranges from comparable banking and broker-dealer engagements — not client-specific results. Your engagement baseline is captured in Discovery and reported weekly during Run; Compliance and Model Risk co-sign the Build deliverables.
Objections we hear most often
We already have SharePoint / Glean / intranet search — why this?+
Enterprise search returns documents and ranks links; it does not enforce information barriers at the retrieval layer, it does not distinguish a current policy from a superseded one, and it cannot refuse to answer when grounding is missing. We give you cited answers from approved sources of record only, MNPI segregation mirroring your wall-crossing model, version-and-supersession awareness, a reviewer queue on consequential answers, and a tamper-evident audit log your examiners can query. The prompts, retrieval index, and eval harness live in your cloud — not a closed box.
Why not just let the desk use ChatGPT?+
A generic LLM has no access to your policies, no concept of your information barriers, no source-of-record citations, and no recordkeeping — and it will confidently state a regulatory position that does not exist. Pasting internal material into it is itself an NPI/MNPI exposure. Our workflow grounds every answer in your approved corpus, cites the document and version, refuses when it cannot ground the answer, segregates MNPI, and logs everything for surveillance and exam.
How do we govern the data and keep MNPI inside the wall?+
Retrieval is partitioned by information barrier and entitlement, inherited from your IAM/SSO roles. MNPI-bearing partitions are unreachable from public-side identities by design; every retrieval and every cross-partition attempt is logged and surveilled alongside your existing communications surveillance. Inference runs with Anthropic Zero-Data-Retention; the index lives in your cloud region; nothing is used for cross-client training. Wall and entitlement configuration is co-signed by Compliance pre-cutover.
Mini SOW
What the Build SOW looks like
Total fee
$31,000 Discovery + Build
Duration
10 weeks to thin-slice production
Week 1–2
Discovery: approved source-of-record inventory, information-barrier and MNPI segregation map co-signed with Compliance, entitlement model from IAM/SSO, labelled question set (200 questions), SR 11-7-aligned model risk framing.
Week 3–5
Partitioned retrieval index live with effective-date/supersession metadata; information-barrier and entitlement enforcement deployed; tamper-evident audit log + surveillance feed instrumented.
Week 6–7
Cited-answer workflow in shadow mode for one user population (e.g. RM or credit-ops desk); citation-required and refuse-when-ungrounded behaviour validated against the labelled set; reviewer queue UI built.
Week 8–9
Production cutover on the first knowledge domain with consequential-answer review enabled; entitlement and freshness audits running; threshold calibration begins.
Week 10
Expansion plan for the next domain; first model validation + access/freshness audit pack delivered to Compliance and Model Risk; operating dashboard live.
Procurement FAQ
How is PII / NPI / MNPI handled?+
NPI lives inside your cloud region under GLBA Safeguards Rule controls, encrypted at rest and in transit. MNPI sits in segregated retrieval partitions enforced by information barriers and is unreachable from public-side identities. Inference runs with Anthropic Zero-Data-Retention; content is not retained by the model provider and is not used for training. Access is least-privilege from your SSO, logged, and surveilled.
Does the model train on our data?+
No. Anthropic Zero-Data-Retention is enabled. Your knowledge corpus, queries, and answers are never used for any cross-client improvement or model training, and data stays in your client region/cloud.
What is the exit path?+
Prompt repository, retrieval and entitlement configuration, eval harness, audit-log schema, dashboard and integration code, and the operating runbook all live in your repo and cloud. At engagement end we deprovision within 30 days and hand over a clean repo; the audit log and your source documents remain yours and in place.
Can examiners and internal audit review the workflow?+
Yes. Every query, retrieved document, citation, reviewer disposition, and entitlement decision is in the tamper-evident audit log, queryable on every dimension an examiner would ask. A quarterly audit pack (model validation, access recertification, freshness) is generated automatically and reviewed with Compliance.
Real shipped systems
What our clients say
Below: attributions from active clients. Client identities are withheld in public form pending written approval; live references available to qualified procurement contacts on discovery call.
AI SaaS · DACH region
“They shipped the production version of our pricing brain in 6 weeks, including the billing layer and the onboarding flow. We had been bouncing between contractors for 4 months before.”
Founder, AI Pricing SaaS
Outcome: From 0 to live SaaS with paying customers in 6 weeks. Production billing live, AI onboarding flow shipped, 2 pricing tiers active.
Government-licensed legal services platform · GCC region
“A complete bilingual platform compliant with regulator requirements. Technical quality and delivery speed are outstanding.”
Founding team, regulated legal marketplace
Outcome: Ministry-of-Justice-licensed national legal marketplace, EN/AR bilingual, in 16 weeks. Directory + bookings + legal tools + emergency contacts.
Property management operator · GCC region
“We replaced spreadsheets and 4 disconnected tools with a single OA platform. 55 screens, 47 tables, a voting platform, and an internal portal — all on the same identity layer.”
CTO, multi-region property operator
Outcome: Centralised property operations across multiple owners associations. 14-week first release; 8-week follow-on for the staff portal; 6-week follow-on for e-voting.
Before / after
Concrete deltas from shipped engagements
Owners-association management workflows
Property management operator · GCC
Operator was scaling association count and could not maintain manual coordination. Replaced 4 fragmented tools with a single AI-augmented operational backbone.
Metric
Operational surface area
Before
Fragmented across spreadsheets + email + 4 SaaS tools
After (14 weeks Build phase)
Unified SaaS with 55 screens / 47 normalized tables / cross-app identity
Pricing strategy SaaS onboarding
AI pricing SaaS · DACH
Founder shipping AI-native pricing platform for early-stage SaaS. Discovery + Build delivered a working SaaS with subscription billing and an AI brain that learns from each customer.
Metric
Time-to-pricing for a new founder
Before
3–4 weeks of consultant time + spreadsheets
After (6 weeks total Build)
9-step structured AI workflow, completed in 30–45 minutes
Lawyer discovery and appointment booking
National legal marketplace · GCC
Regulated entity needed to launch the national reference platform for legal services. Delivered a Next.js 16 monorepo with bilingual content layer, PDF generation, and police directory.
Metric
Citizen access to certified legal services
Before
Fragmented across social media, no central directory, phone-only booking
After (16 weeks Discovery + Build)
Ministry-licensed bilingual EN/AR marketplace; multi-channel booking; legal tools; emergency hotline
Marketing site + booking funnel
Premium vehicle care specialist · DACH
Niche detailing workshop needed to project premium positioning matching their workmanship. AI-assisted copywriting + image art-direction compressed launch time.
Metric
Brand perception alignment
Before
Generic web presence — did not match workmanship quality
After (3 weeks concept-to-live (AI-augmented build))
Premium responsive site, German-market SEO foundation, appointment-oriented CTAs
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
Some banking teams should build internally, especially when they already have strong product, data, security, and operations capacity. Most teams move faster with us because the bottleneck is not only engineering — it is translating messy operational work into a reliable AI-assisted workflow that people will actually use. After 6 to 12 months you can absorb the operating model internally or keep us as a managed execution partner.
What to ask us before signing
- Ask for a workflow map that shows intake, retrieval, generation, review, escalation, system updates, and measurement.
- Ask for an evaluation plan using real examples from banking, not only generic test prompts.
- Ask how we will move search success, time saved, knowledge freshness, and repeated question reduction within the first 30 to 60 days.
- Ask which parts of the process remain human-owned and why.
- Ask for our exit plan: what stays with you if the engagement ends.
Recommended first project
Pick the knowledge management flow that has three properties: high enough weekly volume to produce a labelled test set quickly, structured enough to evaluate, and reversible if a decision is wrong. That is the wedge that ships fast, proves adoption, and earns the credibility to extend into the harder cases. The first 30 days are spent on the labelled test set, the integration to core banking, and the thin-slice workflow. The next 60 days are spent operating the thin slice on real banking traffic, widening the automation envelope week by week. By day 90 you have an empirical track record, not a vendor's projection, and the next workflow can be scoped against that evidence.
Frequently asked questions
How do you automate knowledge management in banking with AI?+
Three phases. Discovery (2 weeks) produces the labelled test set, the system map, and the Build statement of work. Build (6-10 weeks) ships a thin-slice production deployment on top of core banking and adjacent systems, with versioned prompts and a reviewer queue. Run (optional, month-to-month) operates the workflow weekly against search success, time saved, knowledge freshness, and repeated question reduction.
What does it cost to automate knowledge management for banking teams?+
Three phases, billed separately. Discovery sprint: $6k (2-week sprint). Build engagement: $22k–$30k (7-10 weeks). Run retainer: $3k–$5k / mo (optional, hourly bank also available). ~$34k–$60k typical year 1 (60% take the run option for ~6 months). Source curation, retrieval architecture, evaluation harness, and decision dashboards.
What is the best AI agent for knowledge management in banking?+
There is no single "best" off-the-shelf agent for knowledge management in banking — the right architecture depends on your core banking setup, your data, and your risk profile. We typically combine a frontier LLM (Claude, GPT-4-class, or Gemini) with a retrieval layer over your approved sources, tool-use for core banking and CRM integrations, and a reviewer queue. We benchmark candidate models against a labelled test set during Discovery and pick the one with the best accuracy/cost ratio for your workflow.
How long does it take to deploy AI knowledge management for banking?+
End-to-end lead time from kickoff to thin-slice production: 6-10 weeks. End-to-end to full operating envelope: 10-14 weeks. search success, time saved, knowledge freshness, and repeated question reduction is instrumented from day one of Build; the dashboard goes live by week 4-5; production traffic starts by week 6-8. By 90 days, leadership has a 30-60 day record of operating performance against the Discovery baseline.
What do we own, and what do you own?+
We own the workflow design, the prompts, the retrieval architecture, the evaluation harness, and weekly improvement. Your bank executives, retail banking leaders, risk teams, and digital transformation owners team owns data access, policy, exception approval, and final commercial decisions. At the end of the engagement, every prompt, eval, and config is handed over — no lock-in.
How do you guarantee AI answer quality for knowledge management in banking?+
We curate sources, run an evaluation harness against a labelled test set, and require citations for every generated answer. We report on search success, time saved, knowledge freshness, and repeated question reduction and on test-set accuracy weekly.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
search success, time saved, knowledge freshness, and repeated question reduction measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with core banking and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on banking engagements. Cited here so you can verify and dig deeper.
- BIS Financial Stability Institute
- Build for the Future: AI Maturity Survey — BCG
- Generative AI in the Enterprise — Deloitte AI Institute
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — Lewis et al., Meta AI Research
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., Stanford
- AI in Banking: A New Imperative — Federal Reserve Bank of Boston
- EBA Report on the Use of AI in Banking — European Banking Authority
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Banking engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.