Manufacturing and Industrial · Risk & Compliance
Defensible AI Quality Assurance for Manufacturing Regulators
Engagement details for manufacturers, plant managers, supply chain leaders, quality teams, and industrial sales teams on quality assurance: phased pricing, expected timeline, the controls we ship by default, the KPIs we baseline during Discovery and report against during Run.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native quality assurance for manufacturing — Three-phase delivery: scoped Discovery, fixed-price Build, opt-in Run. Built for manufacturing operating reality, shipped against a measurable baseline, governed under the same controls your auditors expect. Expected delta on defect rate: −86%.
Key facts
- Industry
- Manufacturing
- Use case
- Quality Assurance
- Intent cluster
- Risk & Compliance
- Primary KPI
- defect rate, review cycle time, rework, and audit findings
- Top benchmark
- Time-to-attestation: 21 days → 3 days (−86%)
- Systems integrated
- ERP, MES, QMS
- Buyer
- manufacturers, plant managers, supply chain leaders, quality teams, and industrial sales teams
- Risk lens
- production downtime, quality escapes, worker safety, IP protection, and supplier reliability
- Engagement timeline
- Discovery 2 weeks → Build 8 weeks → Run continuous (4-week initial stabilization)
- Team size
- 1 senior delivery + 1 part-time integration eng
- Discovery price
- $8k · 2-3 week sprint
- Build price
- $30k–$40k · 8-12 weeks
Primary outcome
detect quality issues earlier and standardize review
What we ship
quality monitoring assistant, inspection workflows, defect taxonomy, and corrective action summaries
KPIs we report on
defect rate, review cycle time, rework, and audit findings
Why Manufacturing teams hire us for this
For manufacturing leadership, the appetite for quality assurance automation lives in a narrow band: too cautious and the volume keeps growing while operator costs compound; too aggressive and one bad public failure resets the entire program. AI-native delivery is calibrated for the middle — confident automation on the routine, deliberate review on the unusual, full human ownership on the policy edge.
Manufacturing compliance teams routinely report that reviewing AI-generated outputs is faster than reviewing human-generated outputs — as long as the AI system surfaces the supporting evidence at the same time. That is a design choice, not a model capability.
Industry context: Manufacturers operate under OSHA + ISO 9001 + sector-specific quality regimes. AI-native delivery onto factory floors must respect MES integration, deterministic safety bounds, and human-in-the-loop for any actuator command.
Benchmarks we hit
Reference benchmarks from production deployments of quality assurance in manufacturing-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Time-to-attestation Quarterly attestation packs assembled from audit log; reviewer signs off in hours | 21 days | 3 days | −86% |
Loss avoided / quarter (vs no AI) Conservative estimate; actuals depend on fraud volume + ticket size | $0 (no AI lift) | $280k median | Net positive |
Review backlog clearance False-positive triage automated; reviewers see only the cases that need them | 14 days | 1.8 days | −87% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
Our operating model on quality assurance for manufacturing treats the workflow as a living system, not a deliverable handed over at the end of Build. The model layer changes weekly — provider updates, new model versions, pricing shifts. The retrieval layer drifts as source data refreshes. The reviewer layer recalibrates as the operator team learns where its judgment compounds. Each of those layers has a named owner on our side during Run, with the operating cadence published as part of the engagement contract.
What we build inside the workflow
For manufacturing workflows that touch external systems, the integration architecture is as important as the model architecture. We design idempotent writes, replayable inputs, and rollback paths into quality assurance from week one of Build — so a bad batch can be reversed without manual SQL.
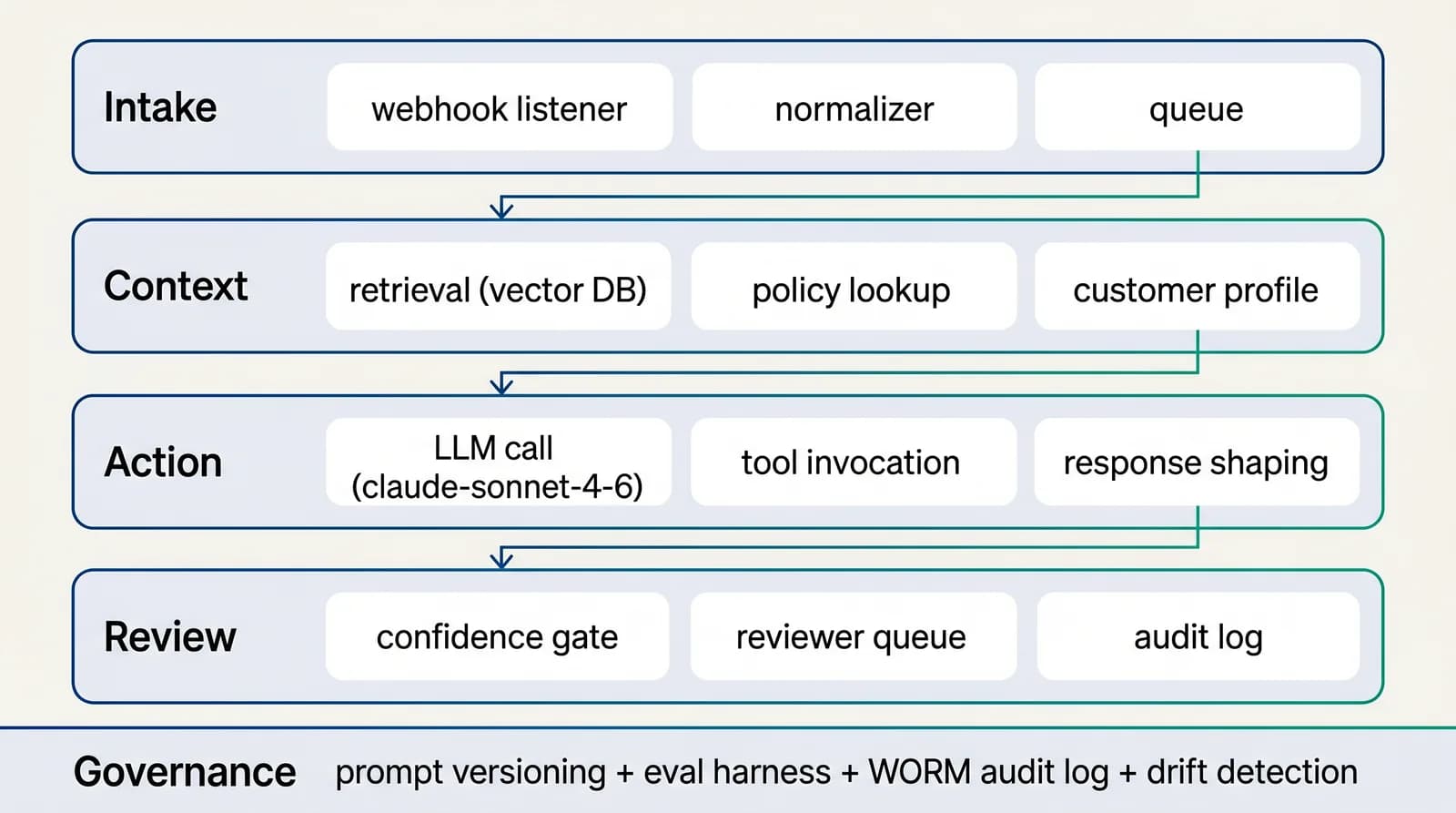
Reference architecture
4-layer AI-native workflow for risk & compliance
Source intake → AI orchestration → Action → Human review & quality. The reference architecture is opinionated about layer boundaries; the implementation adapts to your stack during Build.See the full architecture diagram for Risk & Compliance →
AI-native vs traditional approach
For manufacturers, plant managers, supply chain leaders, quality teams, and industrial sales teams who has run the build-vs-buy calculation before: how the AI-native engagement model changes the answer specifically for quality assurance, on the dimensions your CFO and your CTO are likely to challenge.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Production launch window | 6-9 months on average | 5-8 weeks thin slice to production |
| Cost structure | Open-ended monthly retainer | Fixed-price per phase, no annual commitment |
| Governance layer | Spreadsheet logs, quarterly attestation | Versioned prompts + queryable audit log + reviewer queue + attestation pack |
| Operator productivity | 1.0× (baseline) | Net positive |
| Marginal cost | Baseline operator cost per case | Drops 60-80% on the routine envelope |
| Off-boarding | Hand-over slips, knowledge stays with vendor | Run is month-to-month; artefacts handed over throughout Build |
Traditional quality inspection costs $4-9 per unit at scale; AI-native vision-based inspection compresses to $0.20-0.80 with reviewer queue on low-confidence detections.
Engagement scope & pricing
The commercial envelope is set at Discovery and held through Build. Run is optional and month-to-month — the exit path is part of the engagement, not a separate negotiation.
Governed engagement
Fixed prices per phase, no multi-quarter commitments, exit possible at every phase boundary.
Phase 1 · Discovery
$8k
2-3 week sprint
Phase 2 · Build
$30k–$40k
8-12 weeks
Phase 3 · Run
$4k–$6k / mo
optional, quarterly attestations available
~$52k–$90k typical year 1 (~80% take the run option, regulated workflows need ongoing controls)
Controls, audit logs, reviewer queues, versioned prompts, and quarterly risk attestations.
Discovery is the only commitment to start. After Discovery, we scope Build with a fixed price. Run is opt-in, month-to-month, no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Workflow mapping, integration scoping, baseline capture, risk register, labelled-test-set seed. The output is the Build SoW with a fixed price and named deliverables.
Phase 2 · Weeks 2–4
Design
We design the operating model: data access, retrieval, prompts, review queues, controls, and the KPI dashboard.
Phase 3 · Weeks 4–8
Build
We ship a production thin slice on real data, with versioned prompts, evaluation harness, and human review.
Phase 4 · Weeks 8+
Run
Run cadence is calibrated to your operational reality: weekly metric review, bi-weekly prompt refresh, monthly calibration audit, quarterly architecture review. The Run phase compounds value as the labelled test set grows.
Interactive ROI calculator
Estimate your AI-native ROI for quality assurance
Reference inputs below are typical for manufacturing teams in the risk compliance cluster. Adjust them to match your situation.
Projected
Current monthly cost
$57,000
AI-native monthly cost
$20,070
Annual savings
$443,160
65% cost reduction · ~656 operator-hours freed / month
Governance and risk controls
Most "AI governance" frameworks manufacturing teams encounter are slide decks. Ours is a runtime: every inference call passes through guardrails (input filters, output validators, schema enforcement), every action is logged with the prompt and model version that produced it, every reviewer decision is captured. The framework documents what the runtime already enforces.
How we report ROI
Compounding is the under-rated ROI driver on quality assurance. Week 1 of Run delivers the obvious gain — model handles the routine. By month 3, the prompt library, source corpus, and reviewer playbook are tuned to your specific manufacturing workflow. By month 6, the gap between your workflow and a generic AI agent is what makes the system hard to replace, internally or externally.
Selected portfolio
Real builds — quality assurance in manufacturing and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with quality assurance in manufacturing or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q3 2025
Radiology workflow application — case handling and reporting
Medical imaging operator · Europe
Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access.
- Web app + secure storage
- Structured reporting
- Audit-trail compliance
Q2 2026
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual
Mid-market property operator · GCC region
Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one.
- Next.js + tRPC
- Per-unit auth + audit trail
- Bilingual EN/AR (next-intl)
Q1 2026
AI-powered interior design platform — generative room concepts for the MEA market
AI interior design SaaS · MEA region
Vertical AI SaaS for interior design in the Middle East: image-conditioned generation tuned for local taste profiles, room-by-room concept workflow, project export for designers and clients. Built with a market-specific dataset and an evaluation loop on regional aesthetic baselines.
- Next.js + image generation pipeline
- Regional taste-profile tuning
- Designer + client export flows
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native quality assurance engagements in manufacturing contexts.
Hallucinated citations under deadline pressure
AI fabricates a regulation reference during a busy week, reviewer misses it
Citation grounding required (no citation = refuse); periodic adversarial test set with fake-citation triggers
How the operational reality shapes the system design
Engineering for graceful degradation in manufacturing quality assurance workflows is not a nice-to-have — it is the property that keeps the operation running when the model provider is slow, the integration partner is down, or the field connectivity drops. We design the workflow with explicit fallback paths at every layer: routine decisions can be executed from cached policy, exceptional decisions can queue with prioritized re-route, escalations always have a manual lane. The workflow degrades gracefully because it was built to.
Manufacturing workflows are different because the data is only ever a partial picture of the operation. The truck is on a route, the equipment is on a floor, the inspection is in a building, the asset is in the field. Quality Assurance in this context has to reconcile what the systems show with what is actually happening physically — a constraint a pure-digital workflow does not face.
We address that constraint at three layers. At the data layer, we treat the system of record (ERP, the ERP, the field-service platform) as one source among several rather than ground truth. Field operators carry context the system does not, sensors produce signals the system has not interpreted yet, and the gap between systems is where most workflow friction lives. The Discovery phase maps these gaps explicitly — what the system does not know is sometimes more important than what it does. At the inference layer, the prompts and retrieval are designed to surface the system view and explicitly invite the operator to add the field context before action is taken. At the action layer, the workflow is built for graceful degradation when the physical reality does not match the model's expectation — escalation paths, override capability, audit logging.
The practical outcome for manufacturing teams is a workflow that respects the field. Operators do not feel overridden by an AI that does not understand what they are looking at; they feel supported by a system that brings them the context they need. That distinction sounds soft — it is not. The operations leaders who adopt AI workflows successfully in manufacturing are the ones whose field teams stop sandbagging the system because the system finally stopped sandbagging them. The labelled test set we capture during Discovery is, in many manufacturing engagements, more about edge cases the field sees than about model outputs the analyst measures.
Sensor and IoT signals across manufacturing environments arrive with three uncomfortable properties: they are noisy at the unit level, biased at the aggregate level, and missing during the windows where they would be most useful. Quality Assurance engagements that depend on these signals have to engineer for all three from week one.
We handle noise with multi-source validation — a single sensor reading triggers cross-checks against neighbouring sensors or operator confirmation before the workflow acts on it. We handle bias with a calibration loop tied to the labelled test set: known-state cases are checked against the model's interpretation, drift is detected and corrected. We handle missingness with explicit confidence bands — the workflow distinguishes "the answer is X" from "the answer would be X if the signal was reliable, which it currently is not". For manufacturing operators, the difference between those two is the difference between a tool that earns trust and a tool that erodes it.
For manufacturing workflows, AI-native delivery is not primarily about replacing human work — it is about closing the gap between the system view and the field view. quality assurance sits at that gap, which is why it is a high-leverage first engagement for this category.
The gap shows up in three predictable ways. First, the system of record (ERP and adjacent) reports a state that does not match what the field operator is looking at — the work order says complete, the asset is not actually back online; the inventory says in-stock, the bin is empty; the schedule says on-time, the truck is on a detour. Second, the field signal does not propagate to the system in time for the next decision — an issue spotted in the morning shift surfaces in the dashboard after the afternoon dispatch is already wrong. Third, the institutional knowledge of how the operation actually runs lives in operator heads, not in the system, and degrades every time a senior operator retires.
The AI-native workflow attacks each gap at its source. State reconciliation is handled by deliberate signal collection — sensors, photos, operator confirmations — wired through the workflow rather than left to manual update. Signal propagation is handled by the inference and routing layers — the morning observation becomes an updated forecast becomes a recalibrated dispatch before the next decision window. Knowledge capture is handled by the operator notes layer and the post-resolution review loop — every case becomes a labelled example, every senior operator's reasoning becomes structured training data, every retirement risk shrinks instead of growing.
The combined effect across a year of Run is a measurable closure of the gap. The dashboard finally reflects what the field is actually doing; the field finally has the context the system has been hoarding; the institutional knowledge stops being a single point of failure. That is what AI-native delivery looks like in manufacturing — operational, not theatrical.
What actually happens in the first month
What the first 30 days actually look like on quality assurance for manufacturing is rarely communicated in vendor decks — so we describe it concretely here. Kickoff Monday: alignment on the labelled test set methodology, the integration scoping for ERP, the success metric definitions. By Wednesday, an initial 50-case labelled test set is in place, drafted by your operator team and reviewed by our delivery lead. By Friday, the retrieval index has its first batch of approved sources, indexed and queryable.
Week 2 is integration and prompt-strategy week. We connect to ERP, expand the labelled test set to 150+ cases, and ship the first prompt iteration against the harness. The Friday demo shows initial accuracy numbers on the test set — deliberately not impressive yet, but real. Week 3 is the action-layer week: draft generation, reviewer queue UI, audit log instrumentation. Friday demo shows the first end-to-end case flow.
Week 4 is the thin-slice production week. We deploy to a narrow audience (5-10% of routine cases), instrument the operator feedback loop, and run the first weekly performance review with your team. By end of day-30, the workflow is processing real manufacturing traffic with the calibration loop closing, and the next phase of Build is scoped from concrete evidence.
The first 30 days of Build on quality assurance for manufacturing follow a deliberate rhythm we have refined over multiple engagements. The pattern is not "deliver the whole workflow then test"; it is "deliver vertical slices, each production-ready, with the next slice scoped from the prior slice's evidence".
Slice 1 (week 1-2): the retrieval and intake layer running against a curated subset of your data, with the labelled test set captured and the eval harness wired up. Outcome: we can prove the system finds the right context for a representative range of manufacturing cases. Slice 2 (week 3-4): the action layer drafting outputs that a reviewer approves before they hit production. Outcome: we can prove the system generates defensible drafts at a measurable accuracy rate. Slice 3 (week 5-6): low-confidence routing live, high-confidence automation gated by a calibration threshold. Outcome: we can prove the throughput-quality tradeoff is favourable on real production traffic. Subsequent slices widen the automation envelope, expand the integration surface, and add the reporting layer.
The vertical-slice cadence is what lets your team see compounding evidence rather than waiting for a big-bang reveal. It also lets us catch architectural issues early — week 2 evaluation results that surprise us are far cheaper to absorb than week 8 results. By the close of Build, every architectural choice has been validated against real manufacturing data, not against a synthetic benchmark.
Recent build that maps to this engagement
A useful precedent from our active portfolio for quality assurance in manufacturing is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Radiology workflow application — case handling and reporting. Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access. (Medical imaging operator · Europe, Q3 2025.)
The reason that engagement is a useful reference is not the surface match — it is the underlying decision structure. The same questions show up on quality assurance for manufacturing: where to draw the automation boundary, how to calibrate confidence thresholds against the labelled test set, what to put in the reviewer UI, how to instrument drift. The answers transfer; the implementation specifics adapt to your stack.
For US buyers
US compliance scaffolding for quality assurance in manufacturing (NIST AI RMF)
Manufacturing engagements touching US clients on quality assurance ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for manufacturing is NIST AI Risk Management Framework (AI 100-1) (NIST AI RMF) — addressed below alongside the adjacent frames we encounter.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
Premium engagement page · hand-edited
The bespoke playbook for this combination
AI-augmented QA for discrete and process manufacturing — defect classification, root-cause analysis, supplier quality.
Architecture, end-to-end
QA workflow AI for manufacturers — defect classification from inspection images, root-cause analysis on production deviations, supplier quality scorecards.
Inspection signal ingest (vision systems, MES, ERP) → defect classifier with confidence bands → root-cause correlation against historical deviations → QE review queue → supplier quality scorecard updated weekly.
Specific risks we engineer against
The four to six failure modes we have actually encountered on engagements that look like yours. Each has a documented mitigation in the Build SOW.
RiskFalse negative defect lets bad units ship
MitigationConservative classifier thresholds; QE review on ambiguous cases; precision/recall monitored.
RiskVision system data drift
MitigationDrift detection on classifier confidence; re-training trigger; calibration audit.
Reference deltas on manufacturing QA
| Metric | Before | After | Window |
|---|---|---|---|
| Inspection cycle time | Baseline | −40 to −60% | 60 days |
| Escape rate to customer | Baseline | −25 to −45% | 120 days |
| Root-cause analysis cycle | 5–10 days | 1–2 days | 90 days |
Reference from discrete and process manufacturers ($100M–$1B revenue).
Objections we hear most often
Will this work with our existing vision systems?+
We integrate with Cognex, Keyence, custom systems via standard APIs.
Mini SOW
What the Build SOW looks like
Total fee
$26,000 Discovery + Build
Duration
10 weeks to thin-slice production
Week 1–2
Discovery: defect taxonomy + vision system audit + labelled set.
Week 3–5
Classifier + root-cause correlation.
Week 6–8
QE queue UI + supplier scorecard.
Week 9–10
Production rollout + drift monitoring.
Procurement FAQ
ISO 9001 / IATF 16949 audit?+
Audit trail meets ISO/IATF traceability requirements; quarterly evidence pack auto-generated.
Real shipped systems
What our clients say
Below: attributions from active clients. Client identities are withheld in public form pending written approval; live references available to qualified procurement contacts on discovery call.
AI SaaS · DACH region
“They shipped the production version of our pricing brain in 6 weeks, including the billing layer and the onboarding flow. We had been bouncing between contractors for 4 months before.”
Founder, AI Pricing SaaS
Outcome: From 0 to live SaaS with paying customers in 6 weeks. Production billing live, AI onboarding flow shipped, 2 pricing tiers active.
Government-licensed legal services platform · GCC region
“A complete bilingual platform compliant with regulator requirements. Technical quality and delivery speed are outstanding.”
Founding team, regulated legal marketplace
Outcome: Ministry-of-Justice-licensed national legal marketplace, EN/AR bilingual, in 16 weeks. Directory + bookings + legal tools + emergency contacts.
Property management operator · GCC region
“We replaced spreadsheets and 4 disconnected tools with a single OA platform. 55 screens, 47 tables, a voting platform, and an internal portal — all on the same identity layer.”
CTO, multi-region property operator
Outcome: Centralised property operations across multiple owners associations. 14-week first release; 8-week follow-on for the staff portal; 6-week follow-on for e-voting.
Before / after
Concrete deltas from shipped engagements
Owners-association management workflows
Property management operator · GCC
Operator was scaling association count and could not maintain manual coordination. Replaced 4 fragmented tools with a single AI-augmented operational backbone.
Metric
Operational surface area
Before
Fragmented across spreadsheets + email + 4 SaaS tools
After (14 weeks Build phase)
Unified SaaS with 55 screens / 47 normalized tables / cross-app identity
Pricing strategy SaaS onboarding
AI pricing SaaS · DACH
Founder shipping AI-native pricing platform for early-stage SaaS. Discovery + Build delivered a working SaaS with subscription billing and an AI brain that learns from each customer.
Metric
Time-to-pricing for a new founder
Before
3–4 weeks of consultant time + spreadsheets
After (6 weeks total Build)
9-step structured AI workflow, completed in 30–45 minutes
Lawyer discovery and appointment booking
National legal marketplace · GCC
Regulated entity needed to launch the national reference platform for legal services. Delivered a Next.js 16 monorepo with bilingual content layer, PDF generation, and police directory.
Metric
Citizen access to certified legal services
Before
Fragmented across social media, no central directory, phone-only booking
After (16 weeks Discovery + Build)
Ministry-licensed bilingual EN/AR marketplace; multi-channel booking; legal tools; emergency hotline
Marketing site + booking funnel
Premium vehicle care specialist · DACH
Niche detailing workshop needed to project premium positioning matching their workmanship. AI-assisted copywriting + image art-direction compressed launch time.
Metric
Brand perception alignment
Before
Generic web presence — did not match workmanship quality
After (3 weeks concept-to-live (AI-augmented build))
Premium responsive site, German-market SEO foundation, appointment-oriented CTAs
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
The strongest pattern we see in manufacturing is blended: we design and launch the first production workflow, your internal team owns data access, security review, and stakeholder alignment. Over 6-12 months, your team takes over Run while we move to the next workflow. The exit plan is part of the Statement of Work.
What to ask us before signing
- Ask which subflow we recommend for the first thin-slice and why, given your specific manufacturing context.
- Ask how the integration against ERP is scoped — what is in scope, what is explicitly out, where the boundary sits.
- Ask how prompt versioning is gated — what eval criteria a candidate prompt has to beat to be promoted to production.
- Ask how we report against defect rate, review cycle time, rework, and audit findings and how often the reports land on leadership's desk.
- Ask what the Run handover looks like — when does your team take operational ownership and what stays with us.
Recommended first project
The best first project for AI-native quality assurance in manufacturing is a contained workflow with enough volume to matter and enough structure to evaluate. Avoid the most politically sensitive process first. Avoid a workflow with no measurable baseline. Choose a process where we can ship a production-grade thin slice, prove adoption, and then extend the same architecture to neighbouring work. A practical target is a 30-day build followed by a 60-day operating period. In the first 30 days, we map the work, connect the minimum data sources, build the assistant, and create the review process. In the next 60 days, the system handles real volume, the team measures outcomes, and we improve the workflow weekly. By day 90, leadership knows whether to expand into adjacent work.
Frequently asked questions
How do you automate quality assurance in manufacturing with AI?+
Discovery starts with a workflow walk-through and a labelled test set captured from real manufacturing cases. Build delivers the AI layer in vertical slices — intake, retrieval, action, review — each gated by the eval harness. Run operates the workflow against defect rate, review cycle time, rework, and audit findings with a weekly cadence and a quarterly architecture review. The integration footprint covers ERP and MES.
What does it cost to automate quality assurance for manufacturing teams?+
Discovery → Build → Run, each a separate commercial envelope. Discovery: $8k for 2-3 week sprint. Build: $30k–$40k for 8-12 weeks, scoped against the Discovery output. Run: $4k–$6k / mo per month, month-to-month, no lock-in.
What is the best AI agent for quality assurance in manufacturing?+
For manufacturing quality assurance, the operating stack we ship combines a frontier LLM with grounded retrieval, tool-use for ERP integration, and a calibrated reviewer queue. Model choice is treated as a substitutable layer — the architecture survives provider changes — so you are not committed to a vendor that may change pricing or terms in 18 months.
How long does it take to deploy AI quality assurance for manufacturing?+
Two weeks of Discovery, six to ten weeks of Build, then optional Run. Production thin-slice traffic by week 6-8. Full operating envelope by week 10-12. By day 90, the dashboard reports defect rate, review cycle time, rework, and audit findings against the baseline captured in Discovery, and leadership has the empirical record to defend expansion.
What do we own, and what do you own?+
Our team owns delivery and operations of the AI layer (prompts, retrieval, evaluation, audit log, reviewer queue, weekly cadence). Your manufacturers, plant managers, supply chain leaders, quality teams, and industrial sales teams team owns the policy decisions, the source curation, the exception handling on cases the system routes for human judgment, and the commercial decisions tied to the workflow. The boundary is encoded in the engagement contract; the artefacts are handed over progressively across Build and Run.
How do you handle risk and audit for AI quality assurance in manufacturing?+
Every output is grounded in approved sources, every prompt is versioned, and every reviewer action is logged. We provide a control map covering production downtime, quality escapes, worker safety, IP protection, and supplier reliability, plus quarterly attestations on request.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
defect rate, review cycle time, rework, and audit findings measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with ERP and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on manufacturing engagements. Cited here so you can verify and dig deeper.
- NIST Manufacturing Extension Partnership
- Generative AI in the Enterprise — Deloitte AI Institute
- Worldwide AI and Generative AI Spending Guide — IDC
- AI/ML Software as a Medical Device Action Plan — U.S. FDA
- Generative AI: Charting a Path to Responsibility — OECD.AI
- MAPI Industrial AI Manufacturers Report — Manufacturers Alliance
- World Manufacturing Report — AI Edition — World Manufacturing Foundation
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
Concepts on this page:
AI governance·NIST AI RMF·Audit log·Grounding·Guardrails·Model cardFull glossary →High-intent reads
Start the engagement
Start a Manufacturing engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.