Technology · Revenue & Growth
Automate Lead Qualification in SaaS with AI
For SaaS founders, revenue leaders, customer success teams, and product marketers ready to move lead qualification from manual operation to instrumented AI-native delivery. Below: the workflow we ship, the operating model that keeps it improving, the governance posture, and the commercial envelope.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native lead qualification for SaaS — From Discovery baseline to production traffic in 8-12 weeks, with the operating model — eval harness, reviewer UI, audit log, calibration cadence — handed over as part of Build, not deferred to Run. Expected delta on speed to lead: +45 pts.
Key facts
- Industry
- SaaS
- Use case
- Lead Qualification
- Intent cluster
- Revenue & Growth
- Primary KPI
- speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction
- Top benchmark
- CRM data quality (account completeness): 42% → 87% (+45 pts)
- Systems integrated
- CRM, product analytics, support platforms
- Buyer
- SaaS founders, revenue leaders, customer success teams, and product marketers
- Risk lens
- customer data handling, hallucinated support, security claims, and lifecycle communication quality
- Engagement timeline
- Discovery 2.5 weeks → Build 7 weeks → Run continuous
- Team size
- 2 senior delivery (1 architect + 1 implementer)
- Discovery price
- $5k · 2-week sprint
- Build price
- $15k–$22k · 6-8 weeks
Primary outcome
separate serious buyers from noise faster
What we ship
AI qualification assistant, scoring rubric, routing rules, and CRM governance
KPIs we report on
speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction
Why SaaS teams hire us for this
The reason lead qualification is a high-ROI wedge for SaaS is not the AI capability — it is the gap between what the workflow currently is (siloed, inconsistent, hard to measure) and what it can become (instrumented, reviewable, improvable). AI is the lever; operating discipline is the fulcrum. We ship both.
Recent industry benchmarks (Gartner, Salesforce Research) show SaaS revenue teams spend 60-70% of their week on non-selling activities. AI-native delivery targets that non-selling block first.
Industry context: SaaS metrics live on NDR (net dollar retention), magic number, and CAC payback. AI-native delivery into PLG funnels needs to respect SOC 2 + ISO 27001 controls and integrate cleanly with Stripe + HubSpot + Segment.
Benchmarks we hit
Reference benchmarks from production deployments of lead qualification in SaaS-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
CRM data quality (account completeness) Forrester B2B Insights: human-only CRM hygiene typically degrades within 6 months | 42% | 87% | +45 pts |
Pipeline conversion (SQL → opportunity) Lift attributed to better intent scoring + faster handoff from AI to AE | 18% | 27% | +50% |
Cost per qualified meeting Includes AI infra cost, SDR time, and overhead allocation | $420 | $95 | −77% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
The control surface we ship for lead qualification is built from the start to be operated by your team, not by us. Each prompt and rule has a named owner, each reviewer queue has an SLA, each metric has a dashboard. By the end of the first Run quarter, your operators can adjust thresholds and refresh sources without us in the loop — we stay available for the architecture-level decisions.
What we build inside the workflow
Concretely for SaaS, we integrate with CRM and product analytics, build the retrieval and reasoning steps for lead qualification, and instrument speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction. The Build deliverable is AI qualification assistant, scoring rubric, routing rules, and CRM governance, paired with a runbook your team can operate without us.
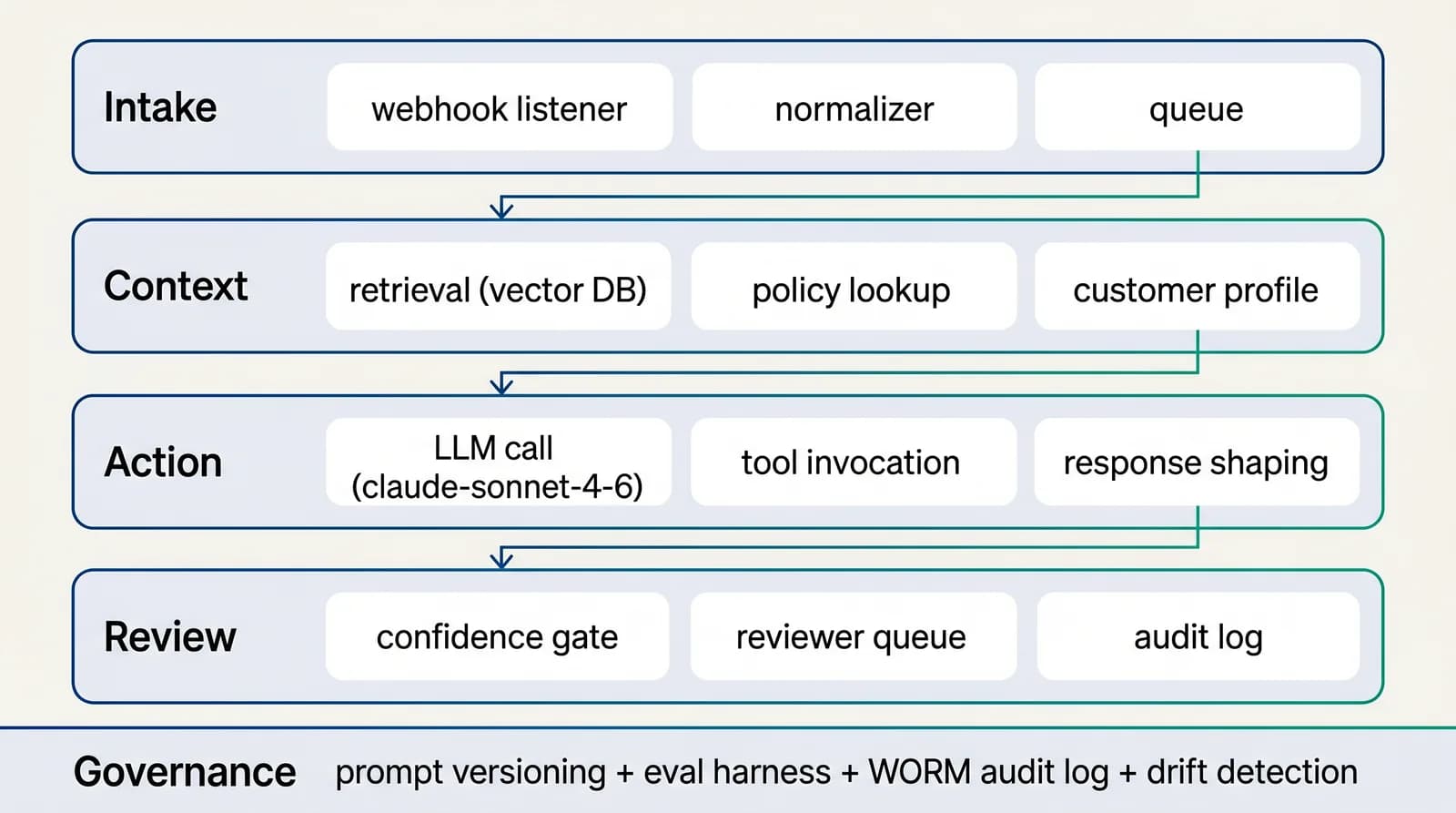
Reference architecture
4-layer AI-native workflow for revenue & growth
Four layers, in the order data flows through them: intake (classify and tag), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases). Each layer is independently observable.See the full architecture diagram for Revenue & Growth →
AI-native vs traditional approach
Side-by-side comparison of an AI-native engagement against the alternatives most SaaS teams evaluate for lead qualification: time to production, pricing model, governance posture, operator throughput, unit cost, exit path.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Lead time to live deployment | 6-12 months | 6-10 weeks (thin slice) |
| Engagement billing | Time-and-materials or annual contract | Phased fixed-price (Discovery → Build → opt Run) |
| Audit posture | Manual logs, periodic review | Versioned prompts, audit logs, reviewer queues, attestations |
| Per-operator capacity | 1.0× (baseline) | +50% |
| Per-case cost | Industry baseline | Sub-dollar marginal cost on routine envelope |
| Exit path | Knowledge transfer takes 6+ months | Documented exit at every phase; artefacts in your repo |
Manual onboarding costs $180-340 per new customer in CS time; AI-native onboarding brings it to $35-80 with reviewer queue on enterprise tier.
Engagement scope & pricing
Lead Qualification delivery is structured as Discovery → Build → opt-in Run, each priced and scoped independently. No multi-quarter retainer commitments.
Revenue engagement
Three commercial envelopes, three deliverables. The next phase is scoped against the evidence the prior phase produced.
Phase 1 · Discovery
$5k
2-week sprint
Phase 2 · Build
$15k–$22k
6-8 weeks
Phase 3 · Run
$2k–$3k / mo
optional, hourly bank also available
~$25k–$45k typical year 1 (60% take the run option for ~6 months)
Outbound, growth, or revenue-ops workflow, integration with your CRM, weekly operating review during Run.
Start with Discovery; nothing more is required to begin. Build is scoped from the Discovery output. Run, if it happens, is month-to-month with no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Workflow mapping, integration scoping, baseline capture, risk register, labelled-test-set seed. The output is the Build SoW with a fixed price and named deliverables.
Phase 2 · Weeks 2–4
Design
Architecture sprint covering the four-layer workflow (intake, context, action, review), the integration footprint, the evaluation methodology, the reviewer UX, and the governance map.
Phase 3 · Weeks 4–8
Build
Vertical-slice delivery against the labelled test set. Each slice ships to production, gated by eval criteria. By end of Build, the workflow is operating on real traffic with the calibration discipline established.
Phase 4 · Weeks 8+
Run
We run the workflow with you weekly, expand into adjacent work, and report against baseline.
Interactive ROI calculator
Estimate your AI-native ROI for lead qualification
Reference inputs below are typical for saas teams in the revenue cluster. Adjust them to match your situation.
Projected
Current monthly cost
$24,000
AI-native monthly cost
$7,920
Annual savings
$192,960
67% cost reduction · ~468 operator-hours freed / month
Governance and risk controls
For SaaS teams operating under customer data handling, hallucinated support, security claims, and lifecycle communication quality, the governance stack we ship is opinionated: source allow-lists curated by your subject-matter expert, prompt versioning gated by your evaluation harness, reviewer queues staffed by your team, audit logs retained per your data policy. We bring the architecture; you bring the policy. The combination is what auditors recognize as defensible.
How we report ROI
The ROI metric that matters most for SaaS leadership on lead qualification is not labor savings — it is opportunity capture. Faster speed to lead means more cases handled in the same window, more revenue, more compliance coverage, more customer trust. We measure both: the costs that drop and the throughput that scales.
Selected portfolio
Real builds — lead qualification in SaaS and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with lead qualification in SaaS or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q2 2026
Digital brand refresh + integrated recruitment platform for an IT consulting firm
Enterprise IT consulting boutique · Europe
Repositioning + redesign for a pure-staffing IT consulting house serving CIO buyers. Editorial architecture tightened around three expertise pillars (IT & SAP, cloud, cybersecurity), premium art direction, conversion-oriented UX, marketing-team-owned Sanity CMS, and an integrated recruitment funnel for senior consultant sourcing.
- Next.js + Framer Motion
- Sanity CMS (marketing-owned)
- Recruitment funnel
Q1 2026
AI pricing system for startup founders — 9-step foundation + personalised AI brain
Founder-led pricing-strategy AI SaaS · DACH
First AI-powered pricing platform for startup founders. Structured 9-step pricing-foundation flow (product, customers, competition, costs, boundaries, model, strategy), personalised AI brain that learns from each business over time, two subscription tiers with money-back guarantee. Built end-to-end including billing, AI orchestration, and onboarding.
- Next.js + TypeScript
- Multi-LLM orchestration
- Subscription billing
Q3 2025
Specialist trades marketing site — roof, facade, renovation services
Construction trades specialist · France
Marketing site for a regional roofing and facade specialist: service architecture covering roof renovation, facade work, and installation services; quote-request workflow with regional catchment routing; SEO foundation built for local intent across nearby municipalities.
- Next.js + responsive
- Local SEO foundation
- Quote-request workflow
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native lead qualification engagements in SaaS contexts.
Volume without quality
Teams scale outbound 5× but reply rate collapses because the AI sends generic pitches
Per-prospect context retrieval (intent data + recent triggers) before any draft. Reviewer queue on first 500 sends to calibrate.
Building inside an organisation that builds for a living
SaaS teams have an unusual buyer profile for AI-native lead qualification: the buyer is technical, the team already ships software, and the bar for what counts as production is high. The engagement model we run with SaaS customers reflects that. We do not sell a black box; we ship code, prompts, and infrastructure-as-code that your engineering team can read, audit, fork, and extend.
The Build phase produces an artefact your engineers can inspect line-for-line. The prompt repository is version-controlled in your Git, not in our SaaS. The retrieval index lives in your cloud account, not ours. The evaluation harness is a CI pipeline you can extend. The reviewer UI is a React app in your codebase. The infrastructure-as-code is in your Terraform. We hand over a working workflow, not a vendor lock-in. The commercial advantage for us is that this transparency turns SaaS engagements into long Run partnerships rather than short Build-and-leave engagements — your engineers find the value, your engineers extend it, and the next workflow we build together starts with shared context instead of cold scoping.
Where our engagement compounds value for SaaS on lead qualification is in the operational discipline around the model layer that engineering teams typically have not encoded yet: prompt versioning with evaluation gates, retrieval freshness with citation tracking, reviewer queues with calibration loops, model swapping with regression suites. Your team has shipped plenty of code; what we bring is the operating model for AI-native code specifically.
The SaaS engagement model for lead qualification is built around a hard constraint: your engineers will read every line of code we ship, and the line they would not have written themselves is the line that becomes the conversation. We design for that conversation from day one.
The prompt layer is documented at the rationale level, not just the syntax level — why this structure, why this retrieval shape, why this confidence threshold. The evaluation harness is structured as a test suite your team would write if they had three months to think about it. The reviewer UI is a React app with explicit state management, not a black box. The deployment pipeline is your existing CI, with our additions as standard GitHub Actions or equivalent. The artefacts we ship are the artefacts a senior engineer at your team would have shipped, with the prompts and evaluation discipline as the differentiator.
What we bring that your team would have spent six months reinventing is the operational discipline around the model layer. Prompt versioning that survives team turnover. Retrieval freshness that survives data-source schema drift. Reviewer queues that survive scale. Model swapping that survives provider outages. We have shipped the pattern enough times to know which pieces fail under real production load, which pieces look good in a slide deck and break in week three, and which pieces compound value over a year of operation. That experience is the engagement, not the code.
Week-by-week shape of the Build phase
Week 1 — Discovery handover and labelled test set capture. We sit with the operator team running lead qualification today, watch a working day end to end, and capture 200+ real cases as the labelled test set. By Friday we have the workflow map, the system inventory (CRM, product analytics, and adjacent), the risk register, and the success metrics aligned with your KPI of speed to lead.
Week 2 — Architecture and integration scoping. We design the four-layer workflow (intake, context, action, review), confirm the retrieval shape, lock the prompt strategy direction, and produce the integration plan against CRM. The output is the Build statement of work with a fixed price and a named deliverable per phase.
Week 3-4 — Build sprint 1: retrieval and intake. We stand up the retrieval index against your approved sources, build the intake classifier, instrument the audit log, and run the first eval cycle against the labelled test set. The thin slice is functional but not production-deployed.
Week 5-6 — Build sprint 2: action and review. We ship the action layer, build the reviewer queue UI, calibrate the confidence thresholds against the labelled test set, and onboard the first reviewer cohort. By end of week 6 the workflow is processing low-stakes production traffic with full audit logging.
The rest of the Build phase widens the production envelope case-by-case based on the reviewer feedback loop. By the end of Build, lead qualification for SaaS is running on real traffic with the operating cadence already established.
The Build phase rhythm for lead qualification in SaaS is engineered for the bottleneck most teams hit at the end of week 2: ambition outrunning evidence. We engineer for the opposite — evidence first, ambition calibrated to it.
Week 1 produces the discovery report, the labelled test set, the integration plan, the risk register, the success metrics. Week 2 stands up the retrieval index, the intake classifier, the eval harness, the audit log. Week 3 wires the action layer with reviewer approval, runs the first three eval cycles, produces the first calibration report. Week 4 ships the thin slice to a narrow production audience (5-10% of routine cases), instruments the operator feedback loop, and runs the first weekly review.
By day 30, the dashboard is live, the system is processing real SaaS cases, the operator team is engaging with the reviewer queue, the eval harness is gated on every change, and the next two weeks of Build are scoped from concrete evidence rather than initial assumptions. Days 31-45 widen the production envelope to 40-60% of routine cases. Days 46-60 absorb the remaining routine envelope and start handling the first tranche of exceptional cases. By the close of Build (day 60-70), the workflow is operating at its target envelope with the calibration discipline in place to handle drift, edge cases, and future model changes.
A working example of this pattern
The closest pattern reference we ship for lead qualification in SaaS is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Digital brand refresh + integrated recruitment platform for an IT consulting firm. Repositioning + redesign for a pure-staffing IT consulting house serving CIO buyers. Editorial architecture tightened around three expertise pillars (IT & SAP, cloud, cybersecurity), premium art direction, conversion-oriented UX, marketing-team-owned Sanity CMS, and an integrated recruitment funnel for senior consultant sourcing. (Enterprise IT consulting boutique · Europe, Q2 2026.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to SaaS (CRM and the adjacent systems) and the prompt strategy tuned to the lead qualification vernacular in your category.
For US buyers
US compliance scaffolding for lead qualification in SaaS (CCPA / CPRA, NIST AI RMF)
SaaS engagements touching US clients on lead qualification ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for SaaS is California Consumer Privacy Act / California Privacy Rights Act (CCPA / CPRA) — addressed below alongside the adjacent frames we encounter.
CCPA / CPRA
California Consumer Privacy Act / California Privacy Rights Act
Authority: California Privacy Protection Agency (CPPA)
- Scope
- California resident data rights (access, deletion, opt-out of sale/sharing), sensitive personal information, automated decision-making opt-out (proposed regs).
- How we ship inside it
- California-touching engagements ship with consumer-rights workflows: access request handling, deletion within 45 days, opt-out signals (GPC) honored at the retrieval layer. Automated-decision-making disclosures align with proposed CPPA regulations.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
SaaS teams that build successfully in-house tend to have an existing ML platform, a labelled data culture, and a product manager dedicated to the workflow. If any of those is missing, the project tends to stall at proof-of-concept. We replace those three dependencies with a scoped engagement and a senior delivery team.
What to ask us before signing
- Ask for a 30/60/90-day plan with named deliverables, not a vague phase description.
- Ask how we handle the long tail of edge cases the operator team has never encoded — escalation, calibration, capture.
- Ask for the model and provider strategy — single-model, multi-model, fallback paths, cost forecasting.
- Ask how the reviewer queue UX is designed and whether your operator team can shape it during Build.
- Ask for references from SaaS-adjacent engagements — sector, scope, and outcome dimensions.
Recommended first project
Pick the lead qualification flow that has three properties: high enough weekly volume to produce a labelled test set quickly, structured enough to evaluate, and reversible if a decision is wrong. That is the wedge that ships fast, proves adoption, and earns the credibility to extend into the harder cases. The first 30 days are spent on the labelled test set, the integration to CRM, and the thin-slice workflow. The next 60 days are spent operating the thin slice on real SaaS traffic, widening the automation envelope week by week. By day 90 you have an empirical track record, not a vendor's projection, and the next workflow can be scoped against that evidence.
Frequently asked questions
How do you automate lead qualification in SaaS with AI?+
We map the existing lead qualification workflow inside SaaS, identify the high-volume, high-structure tasks, and build an AI agent that handles those tasks while routing low-confidence cases to a human reviewer. The build connects to your CRM, product analytics, support platforms, runs against a labelled test set, and ships behind a reviewer queue before it sees production traffic. We then operate it, measure speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction, and improve it weekly.
What does it cost to automate lead qualification for SaaS teams?+
~$25k–$45k typical year 1 (60% take the run option for ~6 months). The structure: $5k Discovery (2-week sprint) → $15k–$22k Build (6-8 weeks) → optional $2k–$3k / mo Run. Outbound, growth, or revenue-ops workflow, integration with your CRM, weekly operating review during Run.
What is the best AI agent for lead qualification in SaaS?+
Model selection on lead qualification for SaaS happens against five criteria: quality on your labelled test set, cost per inference at your projected volume, latency budget for the user-facing path, provider reliability over 12-18 months, contractual data-handling posture. We bring the comparative methodology from prior engagements and run it during Build; the winning model is the one that survives all five, not the one that wins the demo.
How long does it take to deploy AI lead qualification for SaaS?+
A thin-slice deployment in 2-week sprint after Discovery, with real SaaS data and real reviewers. The full Build phase runs 6-8 weeks. By day 90, speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction is instrumented, the team has a baseline, and leadership has the data needed to decide on expansion into adjacent SaaS workflows.
What do we own, and what do you own?+
What we ship as code lives in your repository under your IAM. The prompts, the evaluation harness, the integration code, the reviewer UI, the infrastructure-as-code — all in your Git, not in our SaaS. We bring the engineering, the operating discipline, and the cadence; you bring the data, the policy, and the operator team. The handover is documented from day one of Build, not deferred to the end.
Where does revenue lift actually come from on this engagement?+
Four channels. Throughput per operator (same team, more cases). Conversion lift on the long tail of cases that previously fell through. Cycle-time compression on the decision path. Measurement consistency — the dashboard finally reflects what the operation is actually doing, which feeds the next round of optimisation. All four roll up to speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
speed to lead, MQL to SQL conversion, sales acceptance rate, and wasted meeting reduction measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with CRM and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on SaaS engagements. Cited here so you can verify and dig deeper.
- NIST Secure Software Development Framework
- Worldwide AI and Generative AI Spending Guide — IDC
- Hype Cycle for Artificial Intelligence — Gartner
- B2B Buying Disconnect: Buying Decisions are Made Without Sellers — Forrester
- Generative AI Impact on Marketing & Sales — McKinsey
- Bessemer State of the Cloud — Bessemer Venture Partners
- ChartMogul SaaS Benchmarks — ChartMogul
- OpenView SaaS Benchmarks — OpenView Partners
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a SaaS engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.