Supply Chain · Customer Experience
An AI-Native Field Service Engagement for Logistics CX
A scoped engagement page for 3PLs, freight brokers, carriers, warehouse operators, and supply chain leaders evaluating field service. We cover deliverables, timeline, pricing, controls, and the reporting cadence we run during the Build and optional Run phases.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native field service for logistics — Three-phase delivery: scoped Discovery, fixed-price Build, opt-in Run. Built for logistics operating reality, shipped against a measurable baseline, governed under the same controls your auditors expect. Expected delta on first time fix rate: +24 pts.
Key facts
- Industry
- Logistics
- Use case
- Field Service
- Intent cluster
- Customer Experience
- Primary KPI
- first time fix rate, travel time, SLA attainment, and service margin
- Top benchmark
- First-contact resolution rate: 54% → 78% (+24 pts)
- Systems integrated
- TMS, WMS, ERP
- Buyer
- 3PLs, freight brokers, carriers, warehouse operators, and supply chain leaders
- Risk lens
- service failures, shipment visibility, customs documentation, safety, and margin leakage
- Engagement timeline
- Discovery 2.5 weeks → Build 7 weeks → Run continuous
- Team size
- 2 senior delivery (1 architect + 1 implementer)
- Discovery price
- $5k · 2-week sprint
- Build price
- $18k–$25k · 6-9 weeks
Primary outcome
increase field productivity and reduce repeat visits
What we ship
dispatch assistant, technician knowledge base, parts predictor, and visit summary workflow
KPIs we report on
first time fix rate, travel time, SLA attainment, and service margin
Why Logistics teams hire us for this
Three forces compound on logistics teams trying to scale field service: rising operator cost, rising volume, and rising quality expectations. Headcount-led growth is no longer mathematically viable; AI-native delivery is the only path that lets quality go up *while* unit cost goes down — provided the operating discipline is in place from day one.
Forrester customer-centricity research finds that consistent quality matters more than peak quality in logistics service. AI-native automation excels at consistency — it is poor at the surprising edge case. That tradeoff is the heart of our design.
Industry context: Mid-market and enterprise operators face the same fundamental tradeoff: AI must compress operational cycle time while remaining auditable and integrable with existing systems of record.
Benchmarks we hit
Reference benchmarks from production deployments of field service in logistics-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
First-contact resolution rate Zendesk CX Trends benchmark; lift attributed to context retrieval before agent touch | 54% | 78% | +24 pts |
Median response time AI handles 80% of intents; humans handle the 20% that need judgment | 4h 22min | 47s | −99.7% |
Support cost per case (fully loaded) Includes AI tokens, agent time, QA review, infra overhead | $8.40 | $2.10 | −75% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
The unit of operation on field service is not a model call — it is a case (a ticket, a claim, a record, a request) that flows from intake to outcome. We instrument every case end-to-end: where it came in, what context it was matched against, what action was taken, who reviewed it, how long it took, whether the outcome held. For logistics teams, that case-level telemetry is what makes the workflow operationally legible.
What we build inside the workflow
The hardest engineering question in Build for field service in logistics is not the prompt or the model — it is the data access layer. We spend Discovery on identifying which sources the workflow actually needs, which are reachable through clean APIs, which need ETL, which have permission issues, which carry latency or freshness constraints. The Build statement of work names which sources are in scope and which are explicitly out of scope. The cleanest engagements are the ones where the data access plan is signed off before any code is written.
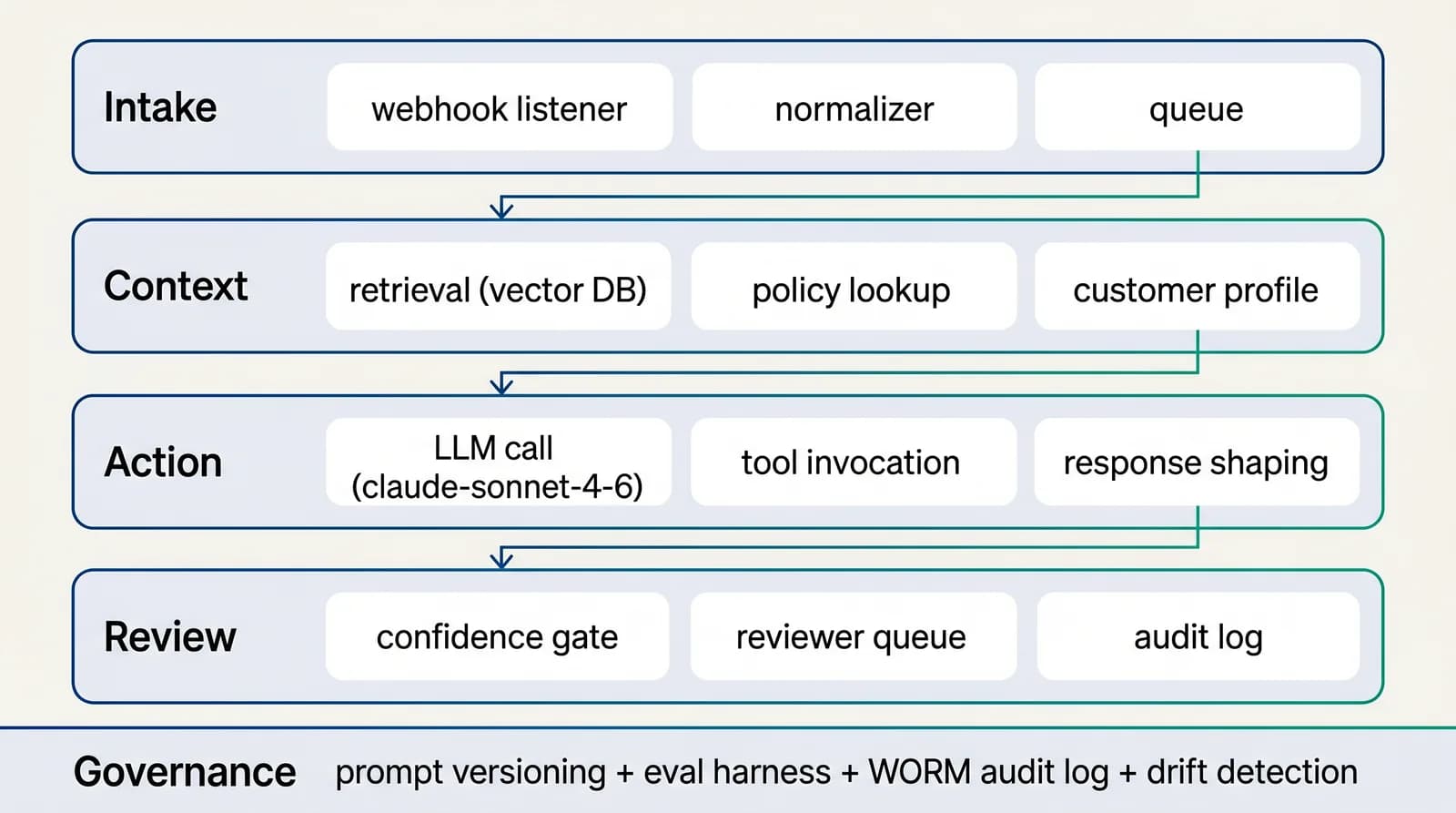
Reference architecture
4-layer AI-native workflow for customer experience
Four layers, in the order data flows through them: intake (classify and tag), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases). Each layer is independently observable.See the full architecture diagram for Customer Experience →
AI-native vs traditional approach
Logistics teams considering field service typically weigh four paths: in-house build with new hires, BPO contract, generic AI SaaS, or AI-native engagement. The table below compares the trade-offs.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Production launch window | 6-9 months on average | 5-8 weeks thin slice to production |
| Cost structure | Open-ended monthly retainer | Fixed-price per phase, no annual commitment |
| Governance layer | Spreadsheet logs, quarterly attestation | Versioned prompts + queryable audit log + reviewer queue + attestation pack |
| Operator productivity | 1.0× (baseline) | −99.7% |
| Marginal cost | Baseline operator cost per case | Drops 60-80% on the routine envelope |
| Off-boarding | Hand-over slips, knowledge stays with vendor | Run is month-to-month; artefacts handed over throughout Build |
Traditional process automation projects cost $80-200k+ with 6-12 month payback; AI-native engagements deliver thin-slice production in 6-8 weeks with measurable baseline-vs-actuals reporting.
Engagement scope & pricing
Phased and fixed-price by default. You commit one phase at a time, with a defined deliverable per phase.
CX engagement
Discovery → Build → Run, each phase committable on its own. No bundling, no annual minimum.
Phase 1 · Discovery
$5k
2-week sprint
Phase 2 · Build
$18k–$25k
6-9 weeks
Phase 3 · Run
$2k–$3k / mo
optional, hourly bank also available
~$28k–$48k typical year 1 (60% take the run option for ~6 months)
Customer journey design, escalation handling, tone calibration, and CX KPI reporting.
Start with Discovery; nothing more is required to begin. Build is scoped from the Discovery output. Run, if it happens, is month-to-month with no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Workflow mapping, integration scoping, baseline capture, risk register, labelled-test-set seed. The output is the Build SoW with a fixed price and named deliverables.
Phase 2 · Weeks 2–4
Design
Architecture sprint covering the four-layer workflow (intake, context, action, review), the integration footprint, the evaluation methodology, the reviewer UX, and the governance map.
Phase 3 · Weeks 4–8
Build
Vertical-slice delivery against the labelled test set. Each slice ships to production, gated by eval criteria. By end of Build, the workflow is operating on real traffic with the calibration discipline established.
Phase 4 · Weeks 8+
Run
We run the workflow with you weekly, expand into adjacent work, and report against baseline.
Interactive ROI calculator
Estimate your AI-native ROI for field service
Reference inputs below are typical for logistics teams in the customer experience cluster. Adjust them to match your situation.
Projected
Current monthly cost
$42,000
AI-native monthly cost
$13,000
Annual savings
$348,000
69% cost reduction · ~920 operator-hours freed / month
Governance and risk controls
AI-native workflows need a risk model that fits the sector. In logistics, the central concerns are service failures, shipment visibility, customs documentation, safety, and margin leakage. We ship five controls on every engagement: every answer or recommendation is grounded in approved sources; the system keeps a record of inputs, outputs, model versions, and reviewers; low-confidence or high-impact cases route to humans; quality is measured with a labelled test set of real examples; your team owns the final policy and escalation rules.
How we report ROI
ROI on field service compounds through four channels: labor leverage (same team, more volume), quality consistency (fewer missed steps, less rework), cycle-time compression (decisions and handoffs happen faster), and learning speed (every case improves the taxonomy and playbook). In logistics, that shows up in on-time delivery, tender acceptance, cost per shipment, exception resolution time, and fill rate.
Selected portfolio
Real builds — field service in logistics and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with field service in logistics or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q3 2025
On-demand regional aviation booking — flexible flight network across smaller cities
Regional aviation operator · DACH
Booking and operations stack for an on-demand regional aviation network connecting secondary cities. Customer-facing booking flow with dynamic availability, operator-side dispatch tools, route economics dashboards. Designed for a sustainable flight-network operating model rather than fixed-schedule airline patterns.
- Next.js + native-app companion
- Dynamic availability engine
- Operator dispatch console
Q2 2026
Internal staff portal — multi-association operations in role-based dashboards
Mid-market property operator · GCC region
Role-scoped portal for property managers, accountants, and maintenance staff. Reuses the OA data model from the management SaaS (zero duplication), adds multi-association switching, maintenance ticket lifecycle, financial reporting, and document storage tied to each association workspace.
- Next.js + tRPC
- NextAuth role-based access
- Drizzle ORM shared schema
Q2 2026
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual
Mid-market property operator · GCC region
Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one.
- Next.js + tRPC
- Per-unit auth + audit trail
- Bilingual EN/AR (next-intl)
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native field service engagements in logistics contexts.
Escalation invisible
Customer trapped in AI loop with no obvious 'talk to human' path; CSAT crashes
Escalation surface designed before automation; 'human now' button on every screen + voice escalation
What the field reality means for the architecture
The instinct in logistics field service engagements is to centralize — pull all the field data into the central system, run AI on the consolidated view, push decisions back out. That instinct is half right. The data does need to be consolidated for analysis; the decisions often do not need to be centralized to be made well.
Our architecture for logistics workflows is hybrid by default. The central layer holds the consolidated view, the model registry, the retrieval index, the analytics. The field layer holds the lightweight decision interface, the offline-capable capture surface, and the local cache for routine decisions. The boundary is drawn case by case: routine field service decisions execute at the edge with central audit; exceptional decisions route to the central reviewer queue with full context; policy decisions stay with the named human owner regardless of confidence.
The practical reason for this hybrid is latency and resilience. Field operators making time-sensitive decisions in logistics cannot wait for a round-trip to the central system on every routine case. The edge layer handles the routine with the central layer's policies pre-distributed. When connectivity drops, the routine work continues; exceptional cases queue for connection. When connectivity returns, the queue clears, the central log is updated, the analytics catch up. The operation degrades gracefully instead of breaking sharply, which is the property field operators actually need from a workflow that touches their daily work.
From kickoff to thin-slice production
What the first 30 days actually look like on field service for logistics is rarely communicated in vendor decks — so we describe it concretely here. Kickoff Monday: alignment on the labelled test set methodology, the integration scoping for TMS, the success metric definitions. By Wednesday, an initial 50-case labelled test set is in place, drafted by your operator team and reviewed by our delivery lead. By Friday, the retrieval index has its first batch of approved sources, indexed and queryable.
Week 2 is integration and prompt-strategy week. We connect to TMS, expand the labelled test set to 150+ cases, and ship the first prompt iteration against the harness. The Friday demo shows initial accuracy numbers on the test set — deliberately not impressive yet, but real. Week 3 is the action-layer week: draft generation, reviewer queue UI, audit log instrumentation. Friday demo shows the first end-to-end case flow.
Week 4 is the thin-slice production week. We deploy to a narrow audience (5-10% of routine cases), instrument the operator feedback loop, and run the first weekly performance review with your team. By end of day-30, the workflow is processing real logistics traffic with the calibration loop closing, and the next phase of Build is scoped from concrete evidence.
The first 30 days of Build on field service for logistics follow a deliberate rhythm we have refined over multiple engagements. The pattern is not "deliver the whole workflow then test"; it is "deliver vertical slices, each production-ready, with the next slice scoped from the prior slice's evidence".
Slice 1 (week 1-2): the retrieval and intake layer running against a curated subset of your data, with the labelled test set captured and the eval harness wired up. Outcome: we can prove the system finds the right context for a representative range of logistics cases. Slice 2 (week 3-4): the action layer drafting outputs that a reviewer approves before they hit production. Outcome: we can prove the system generates defensible drafts at a measurable accuracy rate. Slice 3 (week 5-6): low-confidence routing live, high-confidence automation gated by a calibration threshold. Outcome: we can prove the throughput-quality tradeoff is favourable on real production traffic. Subsequent slices widen the automation envelope, expand the integration surface, and add the reporting layer.
The vertical-slice cadence is what lets your team see compounding evidence rather than waiting for a big-bang reveal. It also lets us catch architectural issues early — week 2 evaluation results that surprise us are far cheaper to absorb than week 8 results. By the close of Build, every architectural choice has been validated against real logistics data, not against a synthetic benchmark.
A comparable engagement we have shipped
The closest pattern reference we ship for field service in logistics is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
On-demand regional aviation booking — flexible flight network across smaller cities. Booking and operations stack for an on-demand regional aviation network connecting secondary cities. Customer-facing booking flow with dynamic availability, operator-side dispatch tools, route economics dashboards. Designed for a sustainable flight-network operating model rather than fixed-schedule airline patterns. (Regional aviation operator · DACH, Q3 2025.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to logistics (TMS and the adjacent systems) and the prompt strategy tuned to the field service vernacular in your category.
For US buyers
US compliance scaffolding for field service in logistics (NIST AI RMF)
Logistics engagements touching US clients on field service ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for logistics is NIST AI Risk Management Framework (AI 100-1) (NIST AI RMF) — addressed below alongside the adjacent frames we encounter.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
Premium engagement page · hand-edited
The bespoke playbook for this combination
Last-mile and field-service dispatch optimisation — multi-stop routing, ETA accuracy, exception handling.
Architecture, end-to-end
Dispatch AI for last-mile logistics and field service — real-time multi-stop optimisation, customer ETA accuracy, exception triage on disruptions.
Order + driver + vehicle + traffic + weather ingest → optimisation engine balancing SLA / cost / load / driver hours → dispatch queue with override capability → customer ETA push with confidence band → exception triage on disruptions.
Specific risks we engineer against
The four to six failure modes we have actually encountered on engagements that look like yours. Each has a documented mitigation in the Build SOW.
RiskOptimisation suggests illegal route (HOS violation)
MitigationHours-of-service rules enforced as hard constraints; driver acceptance required on overrides.
RiskCustomer ETA inaccuracy damages NPS
MitigationConfidence band displayed; predictive updates on disruption; under-promise/over-deliver bias.
Reference deltas on last-mile engagements
| Metric | Before | After | Window |
|---|---|---|---|
| Stops/driver/day | Baseline | +15 to +25% | 60 days |
| On-time delivery | 75–85% | 92–97% | 90 days |
| Customer NPS on delivery | +25 | +45 | 120 days |
Reference from last-mile and field service providers.
Objections we hear most often
We have Onfleet/Bringg already+
We sit on top, not in place. AI optimisation augments your existing dispatch platform.
Mini SOW
What the Build SOW looks like
Total fee
$25,500 Discovery + Build
Duration
10 weeks to thin-slice production
Week 1–2
Discovery: route data audit, HOS rules, ETA accuracy baseline.
Week 3–6
Optimisation engine + dispatch queue.
Week 7–8
Customer ETA push + exception triage.
Week 9–10
Production rollout per-region.
Procurement FAQ
Driver privacy?+
Driver telematics processed under GDPR / state-equivalent worker-monitoring rules.
Real shipped systems
What our clients say
Below: attributions from active clients. Client identities are withheld in public form pending written approval; live references available to qualified procurement contacts on discovery call.
AI SaaS · DACH region
“They shipped the production version of our pricing brain in 6 weeks, including the billing layer and the onboarding flow. We had been bouncing between contractors for 4 months before.”
Founder, AI Pricing SaaS
Outcome: From 0 to live SaaS with paying customers in 6 weeks. Production billing live, AI onboarding flow shipped, 2 pricing tiers active.
Government-licensed legal services platform · GCC region
“A complete bilingual platform compliant with regulator requirements. Technical quality and delivery speed are outstanding.”
Founding team, regulated legal marketplace
Outcome: Ministry-of-Justice-licensed national legal marketplace, EN/AR bilingual, in 16 weeks. Directory + bookings + legal tools + emergency contacts.
Property management operator · GCC region
“We replaced spreadsheets and 4 disconnected tools with a single OA platform. 55 screens, 47 tables, a voting platform, and an internal portal — all on the same identity layer.”
CTO, multi-region property operator
Outcome: Centralised property operations across multiple owners associations. 14-week first release; 8-week follow-on for the staff portal; 6-week follow-on for e-voting.
Before / after
Concrete deltas from shipped engagements
Owners-association management workflows
Property management operator · GCC
Operator was scaling association count and could not maintain manual coordination. Replaced 4 fragmented tools with a single AI-augmented operational backbone.
Metric
Operational surface area
Before
Fragmented across spreadsheets + email + 4 SaaS tools
After (14 weeks Build phase)
Unified SaaS with 55 screens / 47 normalized tables / cross-app identity
Pricing strategy SaaS onboarding
AI pricing SaaS · DACH
Founder shipping AI-native pricing platform for early-stage SaaS. Discovery + Build delivered a working SaaS with subscription billing and an AI brain that learns from each customer.
Metric
Time-to-pricing for a new founder
Before
3–4 weeks of consultant time + spreadsheets
After (6 weeks total Build)
9-step structured AI workflow, completed in 30–45 minutes
Lawyer discovery and appointment booking
National legal marketplace · GCC
Regulated entity needed to launch the national reference platform for legal services. Delivered a Next.js 16 monorepo with bilingual content layer, PDF generation, and police directory.
Metric
Citizen access to certified legal services
Before
Fragmented across social media, no central directory, phone-only booking
After (16 weeks Discovery + Build)
Ministry-licensed bilingual EN/AR marketplace; multi-channel booking; legal tools; emergency hotline
Marketing site + booking funnel
Premium vehicle care specialist · DACH
Niche detailing workshop needed to project premium positioning matching their workmanship. AI-assisted copywriting + image art-direction compressed launch time.
Metric
Brand perception alignment
Before
Generic web presence — did not match workmanship quality
After (3 weeks concept-to-live (AI-augmented build))
Premium responsive site, German-market SEO foundation, appointment-oriented CTAs
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
For logistics CTOs already running an ML platform, the value we bring is not engineering — it is the operating model and the productized governance stack. We have shipped enough variations of this workflow to know what fails in production, what reviewer queues look like at scale, and what evaluation cadence actually catches drift. Reusable knowledge, not reusable code.
What to ask us before signing
- Ask which subflow we recommend for the first thin-slice and why, given your specific logistics context.
- Ask how the integration against TMS is scoped — what is in scope, what is explicitly out, where the boundary sits.
- Ask how prompt versioning is gated — what eval criteria a candidate prompt has to beat to be promoted to production.
- Ask how we report against first time fix rate, travel time, SLA attainment, and service margin and how often the reports land on leadership's desk.
- Ask what the Run handover looks like — when does your team take operational ownership and what stays with us.
Recommended first project
Pick the field service flow that has three properties: high enough weekly volume to produce a labelled test set quickly, structured enough to evaluate, and reversible if a decision is wrong. That is the wedge that ships fast, proves adoption, and earns the credibility to extend into the harder cases. The first 30 days are spent on the labelled test set, the integration to TMS, and the thin-slice workflow. The next 60 days are spent operating the thin slice on real logistics traffic, widening the automation envelope week by week. By day 90 you have an empirical track record, not a vendor's projection, and the next workflow can be scoped against that evidence.
Frequently asked questions
How do you automate field service in logistics with AI?+
Discovery starts with a workflow walk-through and a labelled test set captured from real logistics cases. Build delivers the AI layer in vertical slices — intake, retrieval, action, review — each gated by the eval harness. Run operates the workflow against first time fix rate, travel time, SLA attainment, and service margin with a weekly cadence and a quarterly architecture review. The integration footprint covers TMS and WMS.
What does it cost to automate field service for logistics teams?+
Discovery → Build → Run, each a separate commercial envelope. Discovery: $5k for 2-week sprint. Build: $18k–$25k for 6-9 weeks, scoped against the Discovery output. Run: $2k–$3k / mo per month, month-to-month, no lock-in.
What is the best AI agent for field service in logistics?+
For logistics field service, the operating stack we ship combines a frontier LLM with grounded retrieval, tool-use for TMS integration, and a calibrated reviewer queue. Model choice is treated as a substitutable layer — the architecture survives provider changes — so you are not committed to a vendor that may change pricing or terms in 18 months.
How long does it take to deploy AI field service for logistics?+
Two weeks of Discovery, six to ten weeks of Build, then optional Run. Production thin-slice traffic by week 6-8. Full operating envelope by week 10-12. By day 90, the dashboard reports first time fix rate, travel time, SLA attainment, and service margin against the baseline captured in Discovery, and leadership has the empirical record to defend expansion.
What do we own, and what do you own?+
Our team owns delivery and operations of the AI layer (prompts, retrieval, evaluation, audit log, reviewer queue, weekly cadence). Your 3PLs, freight brokers, carriers, warehouse operators, and supply chain leaders team owns the policy decisions, the source curation, the exception handling on cases the system routes for human judgment, and the commercial decisions tied to the workflow. The boundary is encoded in the engagement contract; the artefacts are handed over progressively across Build and Run.
How is the escalation surface designed?+
The path from automation to human is one click, with the customer's context preserved across the handoff. The reviewer queue surfaces low-confidence cases with the supporting evidence pre-assembled so the operator's time goes to judgment, not context-gathering. We track escalation rate as a first-class metric — a falling rate signals genuine learning; a rising rate signals drift.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
first time fix rate, travel time, SLA attainment, and service margin measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with TMS and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on logistics engagements. Cited here so you can verify and dig deeper.
- World Bank Logistics Performance Index
- Worldwide AI and Generative AI Spending Guide — IDC
- Hype Cycle for Artificial Intelligence — Gartner
- The Customer-Centric Index — Forrester
- State of the Connected Customer — Salesforce Research
- MIT Center for Transportation & Logistics — AI Research — MIT CTL
- CSCMP State of Logistics — Council of Supply Chain Management Professionals
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Logistics engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.