Travel and Mobility · Customer Experience
Automate Customer Service in Airports with AI
We design, build, and run AI-native customer service automation for airport operators, passenger experience teams, commercial directors, and ground operations leaders. This page describes the engagement: scope, pricing, timeline, controls, and the KPIs we commit to.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native customer service automation for airports — Production customer service automation for airports delivered in vertical slices, each gated by the labelled test set captured during Discovery, each handing operational ownership progressively to your team. Expected delta on first contact resolution: −99.7%.
Key facts
- Industry
- Airports
- Use case
- Customer Service Automation
- Intent cluster
- Customer Experience
- Primary KPI
- first contact resolution, support cost per case, CSAT, and backlog age
- Top benchmark
- Median response time: 4h 22min → 47s (−99.7%)
- Systems integrated
- AODB, FIDS, baggage systems
- Buyer
- airport operators, passenger experience teams, commercial directors, and ground operations leaders
- Risk lens
- security, passenger safety, airline coordination, and operational resilience
- Engagement timeline
- Discovery 2.5 weeks → Build 7 weeks → Run continuous
- Team size
- 2 senior delivery (1 architect + 1 implementer)
- Discovery price
- $5k · 2-week sprint
- Build price
- $18k–$25k · 6-9 weeks
Primary outcome
reduce support volume while improving response quality
What we ship
AI service desk, escalation paths, knowledge workflows, and quality dashboards
KPIs we report on
first contact resolution, support cost per case, CSAT, and backlog age
Why Airports teams hire us for this
Airports teams running a successful customer service automation program share a posture: they treat the workflow as a long-lived production system, not as a marketing-grade initiative. The KPI dashboard is live by week six, the audit log is queryable by week eight, the operator playbook is hand-over-able by week ten. That posture is built into the engagement contract — not as language but as deliverables.
Zendesk and Salesforce CX research show that airports customers tolerate AI-assisted service when the escalation path to a human is fast and obvious. We design the escalation surface before we design the automation.
Industry context: Airports coordinate 30+ stakeholders per flight (airlines, ground handlers, security, retail, customs). Passenger flow metrics drive concession revenue (every minute saved at security adds ~$0.40 / pax retail spend per ACI benchmarks).
Benchmarks we hit
Reference benchmarks from production deployments of customer service automation in airports-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Median response time AI handles 80% of intents; humans handle the 20% that need judgment | 4h 22min | 47s | −99.7% |
Support cost per case (fully loaded) Includes AI tokens, agent time, QA review, infra overhead | $8.40 | $2.10 | −75% |
CSAT (post-interaction) Lift requires escalation paths kept obvious and fast | 4.1 / 5 | 4.4 / 5 | +0.3 |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
Run cadence on customer service automation is calibrated to airports reality, not consultant fantasy. We do not promise daily prompt updates — we promise weekly. We do not promise instant model swaps — we promise quarterly evaluations against new candidates. The promise is operational reliability, not heroic effort, because heroic effort does not survive the third month.
What we build inside the workflow
A strong implementation starts with a clear inventory of the current work. For Airports, that means understanding how data moves through AODB, FIDS, baggage systems, retail analytics, security operations platforms, who owns each decision, and where handoffs slow the team down. We document current cycle time, error rates, quality review steps, rework, and the volume of requests or records flowing through the process. The automation layer will classifies intent, drafts answers, retrieves policy context, routes complex cases, and learns from resolved tickets.
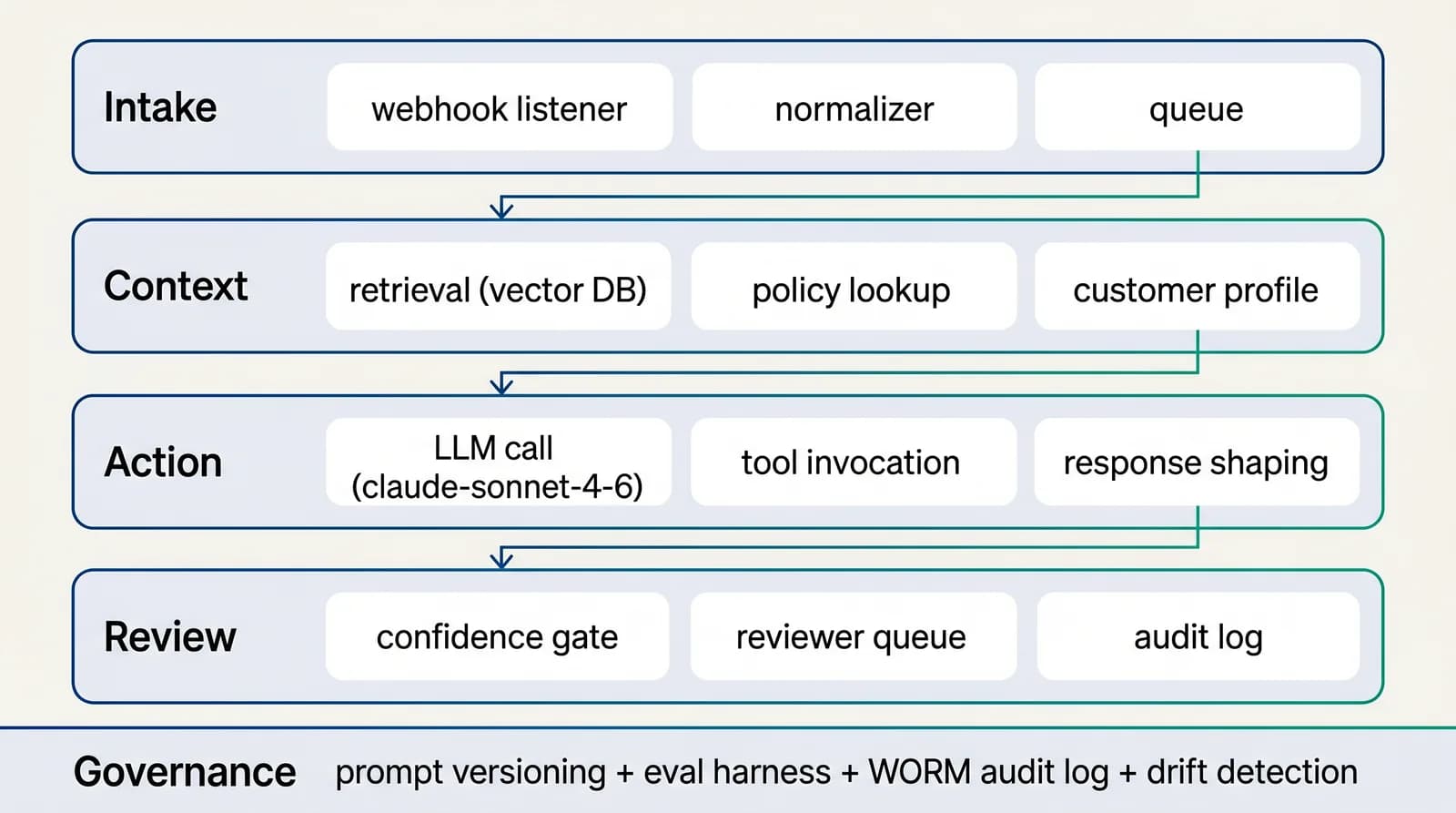
Reference architecture
4-layer AI-native workflow for customer experience
Four layers, in the order data flows through them: intake (classify and tag), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases). Each layer is independently observable.See the full architecture diagram for Customer Experience →
AI-native vs traditional approach
What changes between a traditional customer service automation program in airports and an AI-native engagement is not the goal — it is the architecture, the operating cadence, and the exit posture. The table below makes the differences explicit.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Time to production | Two quarters minimum | Production traffic within 6-10 weeks |
| Pricing model | FTE hourly retainer or fixed staffing | Three independent commercial envelopes |
| Audit / governance | Document-driven, periodic snapshot | Runtime guardrails + audit log + governance map + quarterly attestation |
| Operator throughput lift | 1.0× (baseline) | −75% |
| Cost per unit | Linear with operator headcount | Typically 60-80% lower |
| End-of-engagement | Multi-quarter notice + knowledge loss | Month-to-month Run, full handover plan in Build SoW |
Manual gate coordination costs 4-7 FTE per terminal; AI-native orchestration brings the same coverage to 1-2 FTE with audit-ready logs for IATA Slot Conference disputes.
Engagement scope & pricing
Three phases, three commercial envelopes. Discovery is the only commitment to start; Build and Run are scoped against the Discovery output.
CX engagement
Each phase is independently committable. Discovery is the only one you have to start with.
Phase 1 · Discovery
$5k
2-week sprint
Phase 2 · Build
$18k–$25k
6-9 weeks
Phase 3 · Run
$2k–$3k / mo
optional, hourly bank also available
~$28k–$48k typical year 1 (60% take the run option for ~6 months)
Customer journey design, escalation handling, tone calibration, and CX KPI reporting.
Start with Discovery; nothing more is required to begin. Build is scoped from the Discovery output. Run, if it happens, is month-to-month with no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Two weeks of structured discovery: workflow walk-through, system inventory, decision-owner mapping, baseline KPI capture, risk register. Output: a fixed-scope statement of work for Build.
Phase 2 · Weeks 2–4
Design
We design the operating model: data access, retrieval, prompts, review queues, controls, and the KPI dashboard.
Phase 3 · Weeks 4–8
Build
Build is paced by the evaluation harness: every prompt change must beat the incumbent on the labelled test set across enough metric slices to be promoted. The harness is what makes Build defensible.
Phase 4 · Weeks 8+
Run
Monthly month-to-month Run cadence: Monday metric review, Wednesday prompt and retrieval refresh, Friday calibration audit. The cadence is the deliverable; the prompts are the artefacts that change between cadence cycles.
Interactive ROI calculator
Estimate your AI-native ROI for customer service automation
Reference inputs below are typical for airports teams in the customer experience cluster. Adjust them to match your situation.
Projected
Current monthly cost
$42,000
AI-native monthly cost
$13,000
Annual savings
$348,000
69% cost reduction · ~920 operator-hours freed / month
Governance and risk controls
The governance question that determines success in airports is rarely "is this model safe?" — it is "who owns the decision when the system is uncertain?". We answer that question explicitly for every step: named human owner, defined SLA, escalation path. security, passenger safety, airline coordination, and operational resilience live in those ownership lines, not in the model weights.
How we report ROI
Airports engagements on customer service automation have a predictable ROI shape: months 1-2 negative (engagement cost vs. limited production volume), month 3 break-even (full production traffic, baseline established), months 4-12 strongly positive (compounding leverage as the system tunes to your workflow). We forecast this shape during Discovery so the business case is clear before Build commits.
Selected portfolio
Real builds — customer service automation in airports and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with customer service automation in airports or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q3 2025
On-demand regional aviation booking — flexible flight network across smaller cities
Regional aviation operator · DACH
Booking and operations stack for an on-demand regional aviation network connecting secondary cities. Customer-facing booking flow with dynamic availability, operator-side dispatch tools, route economics dashboards. Designed for a sustainable flight-network operating model rather than fixed-schedule airline patterns.
- Next.js + native-app companion
- Dynamic availability engine
- Operator dispatch console
Q1 2026
AI-powered interior design platform — generative room concepts for the MEA market
AI interior design SaaS · MEA region
Vertical AI SaaS for interior design in the Middle East: image-conditioned generation tuned for local taste profiles, room-by-room concept workflow, project export for designers and clients. Built with a market-specific dataset and an evaluation loop on regional aesthetic baselines.
- Next.js + image generation pipeline
- Regional taste-profile tuning
- Designer + client export flows
Q3 2025
Property marketplace — buy, rent, list across apartments, villas, commercial
Regional real-estate marketplace · GCC region
National real-estate marketplace covering apartments, villas, and commercial property: listing management for agencies and owners, search and filter optimised for local buyer intent, SEO foundation built for long-tail property queries, lead capture per listing with routing to the listing agent.
- Next.js + dynamic SEO routes
- Listing CMS
- Lead routing engine
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native customer service automation engagements in airports contexts.
Tone mismatch with brand
AI drafts feel generic, brand managers refuse to enable autonomous send
Brand-corpus grounding + tone evals on labelled samples before any autonomous send
What the field reality means for the architecture
Sensor and IoT signals across airports environments arrive with three uncomfortable properties: they are noisy at the unit level, biased at the aggregate level, and missing during the windows where they would be most useful. Customer Service Automation engagements that depend on these signals have to engineer for all three from week one.
We handle noise with multi-source validation — a single sensor reading triggers cross-checks against neighbouring sensors or operator confirmation before the workflow acts on it. We handle bias with a calibration loop tied to the labelled test set: known-state cases are checked against the model's interpretation, drift is detected and corrected. We handle missingness with explicit confidence bands — the workflow distinguishes "the answer is X" from "the answer would be X if the signal was reliable, which it currently is not". For airports operators, the difference between those two is the difference between a tool that earns trust and a tool that erodes it.
Most failure modes in airports customer service automation workflows trace back to the same architectural mistake: treating the central system of record as authoritative when the field reality has moved on. We design against that mistake explicitly. The system of record is one input; the operator's observation is another; the sensor or external signal is a third. The workflow reconciles them with a documented precedence rule per case class, and the reconciliation event is logged in a way that can be audited later.
What this looks like in practice for airports on customer service automation: the operator sees a single decision interface that surfaces the three views, flags conflicts, and asks for the override or escalation that breaks the tie. The audit log captures the inputs, the decision, the reasoning, the operator. Six months later, if a regulator, an auditor, or an internal reviewer asks how a particular case was handled, the answer is queryable in one step.
For airports workflows, AI-native delivery is not primarily about replacing human work — it is about closing the gap between the system view and the field view. customer service automation sits at that gap, which is why it is a high-leverage first engagement for this category.
The gap shows up in three predictable ways. First, the system of record (AODB and adjacent) reports a state that does not match what the field operator is looking at — the work order says complete, the asset is not actually back online; the inventory says in-stock, the bin is empty; the schedule says on-time, the truck is on a detour. Second, the field signal does not propagate to the system in time for the next decision — an issue spotted in the morning shift surfaces in the dashboard after the afternoon dispatch is already wrong. Third, the institutional knowledge of how the operation actually runs lives in operator heads, not in the system, and degrades every time a senior operator retires.
The AI-native workflow attacks each gap at its source. State reconciliation is handled by deliberate signal collection — sensors, photos, operator confirmations — wired through the workflow rather than left to manual update. Signal propagation is handled by the inference and routing layers — the morning observation becomes an updated forecast becomes a recalibrated dispatch before the next decision window. Knowledge capture is handled by the operator notes layer and the post-resolution review loop — every case becomes a labelled example, every senior operator's reasoning becomes structured training data, every retirement risk shrinks instead of growing.
The combined effect across a year of Run is a measurable closure of the gap. The dashboard finally reflects what the field is actually doing; the field finally has the context the system has been hoarding; the institutional knowledge stops being a single point of failure. That is what AI-native delivery looks like in airports — operational, not theatrical.
Engineering for graceful degradation in airports customer service automation workflows is not a nice-to-have — it is the property that keeps the operation running when the model provider is slow, the integration partner is down, or the field connectivity drops. We design the workflow with explicit fallback paths at every layer: routine decisions can be executed from cached policy, exceptional decisions can queue with prioritized re-route, escalations always have a manual lane. The workflow degrades gracefully because it was built to.
The tactical playbook for the first 30 days
Our Build cadence on customer service automation for airports is bias-corrected against the two failure modes we have seen kill airports AI projects most often: scoping that drifts week-by-week, and a labelled test set that arrives in week 6 instead of week 1.
We fix the scoping by signing the Build statement of work before any code is written — the deliverables are named, the integration footprint is bounded, the milestones have dates. We fix the labelled test set timing by treating it as the week-1 deliverable. Week 1 is not "scoping week" — it is "labelled-test-set week", because every subsequent engineering decision is measured against that test set.
Week 2: retrieval index live with first batch of approved sources. Week 3: intake classifier scoring against the test set, first calibration report. Week 4: action layer drafting with reviewer approval; first end-to-end case flow. Week 5-6: thin slice in production on 5-15% of routine airports traffic, first weekly review with the operator team. Weeks 7-10: production envelope widens case-class by case-class, calibration loop tunes against the empirical evidence, exceptional cases route to enriched escalation. By day 60-70, the workflow is operating at its target envelope.
Most airports AI projects fail in the first month for the same reason: too much time in scoping, too little in shipping. Our Build phase inverts that ratio deliberately. Week 1 has running code; week 4 has reviewable thin-slice production traffic; week 6 has a defensible accuracy baseline against the labelled test set.
The shape of the first week is opinionated. By end of day Wednesday, the retrieval index is loaded with the first batch of approved sources. By end of day Friday, the intake classifier is hitting the labelled test set with an initial accuracy number. The number is intentionally not impressive — it is a baseline against which weeks 2 and 3 measure progress. Most teams underestimate how motivating that early concrete number is for both the operator team (it stops feeling abstract) and the engineering team (the eval feedback loop is closing).
From week 2 onward the cadence is metric-driven. Every Friday produces a delta report against the labelled test set: which slices improved, which regressed, what the next iteration targets. The operator team participates in the Friday review; their judgment on edge cases becomes the next iteration's prompt or retrieval tweak. By week 6, the system has been through 12-15 evaluation cycles, each with airports-specific calibration, each tied to a documented change. The workflow that hits production at the end of Build is the workflow that has survived a month of empirical correction, not the workflow that looked good in the architecture diagram.
How this rhymes with a recent build
The closest pattern reference we ship for customer service automation in airports is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
On-demand regional aviation booking — flexible flight network across smaller cities. Booking and operations stack for an on-demand regional aviation network connecting secondary cities. Customer-facing booking flow with dynamic availability, operator-side dispatch tools, route economics dashboards. Designed for a sustainable flight-network operating model rather than fixed-schedule airline patterns. (Regional aviation operator · DACH, Q3 2025.)
The reason that engagement is a useful reference is not the surface match — it is the underlying decision structure. The same questions show up on customer service automation for airports: where to draw the automation boundary, how to calibrate confidence thresholds against the labelled test set, what to put in the reviewer UI, how to instrument drift. The answers transfer; the implementation specifics adapt to your stack.
For US buyers
US compliance scaffolding for customer service automation in airports (NIST AI RMF)
Airports engagements touching US clients on customer service automation ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for airports is NIST AI Risk Management Framework (AI 100-1) (NIST AI RMF) — addressed below alongside the adjacent frames we encounter.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
Some airports teams should build internally, especially when they already have strong product, data, security, and operations capacity. Most teams move faster with us because the bottleneck is not only engineering — it is translating messy operational work into a reliable AI-assisted workflow that people will actually use. After 6 to 12 months you can absorb the operating model internally or keep us as a managed execution partner.
What to ask us before signing
- Ask for a workflow map that shows intake, retrieval, generation, review, escalation, system updates, and measurement.
- Ask for an evaluation plan using real examples from airports, not only generic test prompts.
- Ask how we will move first contact resolution, support cost per case, CSAT, and backlog age within the first 30 to 60 days.
- Ask which parts of the process remain human-owned and why.
- Ask for our exit plan: what stays with you if the engagement ends.
Recommended first project
Pick the customer service automation flow that has three properties: high enough weekly volume to produce a labelled test set quickly, structured enough to evaluate, and reversible if a decision is wrong. That is the wedge that ships fast, proves adoption, and earns the credibility to extend into the harder cases. The first 30 days are spent on the labelled test set, the integration to AODB, and the thin-slice workflow. The next 60 days are spent operating the thin slice on real airports traffic, widening the automation envelope week by week. By day 90 you have an empirical track record, not a vendor's projection, and the next workflow can be scoped against that evidence.
Frequently asked questions
How do you automate customer service automation in airports with AI?+
Three phases. Discovery (2 weeks) produces the labelled test set, the system map, and the Build statement of work. Build (6-10 weeks) ships a thin-slice production deployment on top of AODB and adjacent systems, with versioned prompts and a reviewer queue. Run (optional, month-to-month) operates the workflow weekly against first contact resolution, support cost per case, CSAT, and backlog age.
What does it cost to automate customer service automation for airports teams?+
Three phases, billed separately. Discovery sprint: $5k (2-week sprint). Build engagement: $18k–$25k (6-9 weeks). Run retainer: $2k–$3k / mo (optional, hourly bank also available). ~$28k–$48k typical year 1 (60% take the run option for ~6 months). Customer journey design, escalation handling, tone calibration, and CX KPI reporting.
What is the best AI agent for customer service automation in airports?+
There is no single "best" off-the-shelf agent for customer service automation in airports — the right architecture depends on your AODB setup, your data, and your risk profile. We typically combine a frontier LLM (Claude, GPT-4-class, or Gemini) with a retrieval layer over your approved sources, tool-use for AODB and FIDS integrations, and a reviewer queue. We benchmark candidate models against a labelled test set during Discovery and pick the one with the best accuracy/cost ratio for your workflow.
How long does it take to deploy AI customer service automation for airports?+
End-to-end lead time from kickoff to thin-slice production: 6-10 weeks. End-to-end to full operating envelope: 10-14 weeks. first contact resolution, support cost per case, CSAT, and backlog age is instrumented from day one of Build; the dashboard goes live by week 4-5; production traffic starts by week 6-8. By 90 days, leadership has a 30-60 day record of operating performance against the Discovery baseline.
What do we own, and what do you own?+
We own the workflow design, the prompts, the retrieval architecture, the evaluation harness, and weekly improvement. Your airport operators, passenger experience teams, commercial directors, and ground operations leaders team owns data access, policy, exception approval, and final commercial decisions. At the end of the engagement, every prompt, eval, and config is handed over — no lock-in.
How do you protect customer trust when AI handles customer service automation?+
We design tone, escalation, and confidence thresholds with your CX leaders. Low-confidence interactions route to humans, and we track first contact resolution, support cost per case, CSAT, and backlog age alongside qualitative review.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
first contact resolution, support cost per case, CSAT, and backlog age measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with AODB and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on airports engagements. Cited here so you can verify and dig deeper.
- ACI World Airport IT
- Generative AI in the Enterprise — Deloitte AI Institute
- Worldwide AI and Generative AI Spending Guide — IDC
- State of the Connected Customer — Salesforce Research
- Customer Service & AI — Zendesk CX Trends
- ICAO Innovation — International Civil Aviation Organization
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Airports engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.