Healthcare · Operations & Throughput
Deploy an AI Agent for Document Processing in Biotechnology
A scoped engagement page for biotech founders, clinical operations teams, business development leaders, and scientific program managers evaluating document processing. We cover deliverables, timeline, pricing, controls, and the reporting cadence we run during the Build and optional Run phases.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native document processing for biotechnology — An engagement model built around the regulatory and operational realities of biotechnology: document processing delivered with the controls in place from week one, the KPIs aligned with how your team is already measured. Expected delta on documents per hour: −83%.
Key facts
- Industry
- Biotechnology
- Use case
- Document Processing
- Intent cluster
- Operations & Throughput
- Primary KPI
- documents per hour, extraction accuracy, exception rate, and processing cost
- Top benchmark
- Cycle time per transaction: 47 min median → 8 min median (−83%)
- Systems integrated
- ELN, LIMS, clinical trial systems
- Buyer
- biotech founders, clinical operations teams, business development leaders, and scientific program managers
- Risk lens
- scientific validity, IP protection, trial documentation, privacy, and investor communication accuracy
- Engagement timeline
- Discovery 2 weeks → Build 9 weeks → Run continuous (integration-heavy)
- Team size
- 1 senior delivery + 1 part-time domain SME
- Discovery price
- $6k · 2-week sprint
- Build price
- $20k–$28k · 6-10 weeks
Primary outcome
extract meaning from documents at scale
What we ship
document intake pipeline, extraction schema, validation workflow, and exception queue
KPIs we report on
documents per hour, extraction accuracy, exception rate, and processing cost
Why Biotechnology teams hire us for this
Three forces compound on biotechnology teams trying to scale document processing: rising operator cost, rising volume, and rising quality expectations. Headcount-led growth is no longer mathematically viable; AI-native delivery is the only path that lets quality go up *while* unit cost goes down — provided the operating discipline is in place from day one.
World Economic Forum's Lighthouse Network data on biotechnology operations shows that the fastest productivity gains come from automating the work between systems, not inside any single system. AI-native delivery sits in that gap.
Industry context: Mid-market and enterprise operators face the same fundamental tradeoff: AI must compress operational cycle time while remaining auditable and integrable with existing systems of record.
Benchmarks we hit
Reference benchmarks from production deployments of document processing in biotechnology-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Cycle time per transaction Measured on labelled production samples; excludes outliers >2σ | 47 min median | 8 min median | −83% |
Error rate on repeatable steps Quality control sampling; AI-native gates catch errors before downstream propagation | 6.1% | 1.4% | −77% |
Operator throughput per FTE Same operator handles 3.7× the volume thanks to first-pass AI processing | 1.0× (baseline) | 3.7× | +270% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
The cadence we run on document processing for biotechnology is deliberately boring. Monday: pull the metric report against the labelled test set, sample the cases the system was uncertain about, review the reviewer queue calibration. Wednesday: refresh the retrieval index from approved sources, deploy any new prompt versions that beat incumbents on eval, run regression on the test set. Friday: walk through the operator feedback from the week, fold patterns into the playbook, scope the next iteration. Boring is the point — heroic operating cadences do not survive six months.
What we build inside the workflow
We build for the workflow that survives volume and exceptions, not the workflow that impresses in a slide deck. For document processing, that means a labelled test set captured during Discovery, a thin-slice production deployment by week 6, and a weekly evaluation report from day one of Run. document intake pipeline, extraction schema, validation workflow, and exception queue is the visible artefact; the real deliverable is the operating discipline behind it.
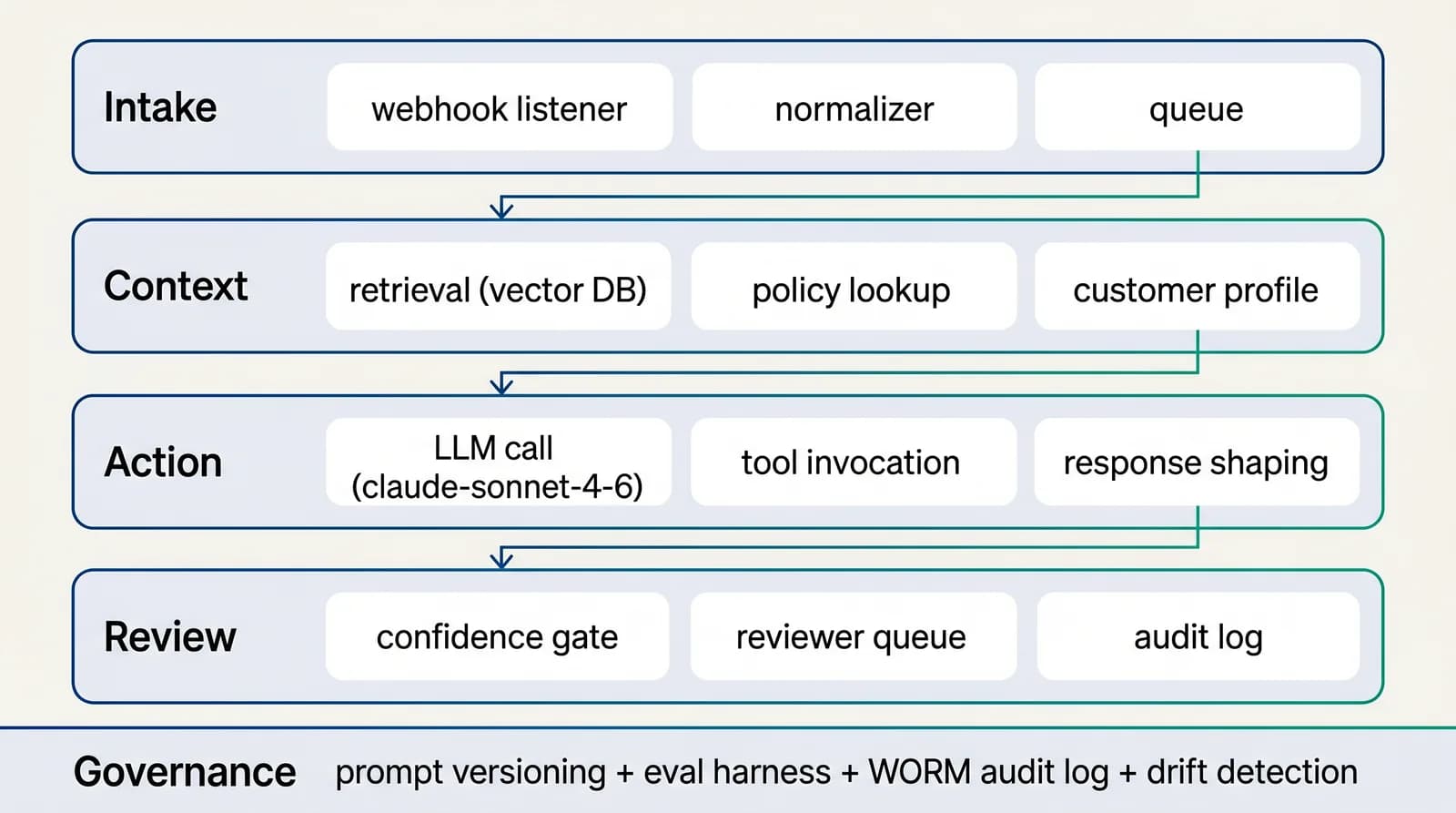
Reference architecture
4-layer AI-native workflow for operations & throughput
The architecture is designed for substitution: any single layer (model, retrieval store, reviewer UI, action client) can be swapped without rewriting the others. That is the property that lets document processing survive 12+ months of provider and pricing change.See the full architecture diagram for Operations & Throughput →
AI-native vs traditional approach
Biotechnology teams considering document processing typically weigh four paths: in-house build with new hires, BPO contract, generic AI SaaS, or AI-native engagement. The table below compares the trade-offs.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Production launch window | 6-9 months on average | 5-8 weeks thin slice to production |
| Cost structure | Open-ended monthly retainer | Fixed-price per phase, no annual commitment |
| Governance layer | Spreadsheet logs, quarterly attestation | Versioned prompts + queryable audit log + reviewer queue + attestation pack |
| Operator productivity | 1.0× (baseline) | −77% |
| Marginal cost | Baseline operator cost per case | Drops 60-80% on the routine envelope |
| Off-boarding | Hand-over slips, knowledge stays with vendor | Run is month-to-month; artefacts handed over throughout Build |
Traditional process automation projects cost $80-200k+ with 6-12 month payback; AI-native engagements deliver thin-slice production in 6-8 weeks with measurable baseline-vs-actuals reporting.
Engagement scope & pricing
Phased and fixed-price by default. You commit one phase at a time, with a defined deliverable per phase.
Operations engagement
Discovery → Build → Run, each phase committable on its own. No bundling, no annual minimum.
Phase 1 · Discovery
$6k
2-week sprint
Phase 2 · Build
$20k–$28k
6-10 weeks
Phase 3 · Run
$2.5k–$4k / mo
optional, hourly bank also available
~$32k–$58k typical year 1 (60% take the run option for ~6 months)
Workflow redesign, system integration, governance, and weekly operating cadence during Run.
The only thing you commit to today is the Discovery sprint. The Build SoW is produced inside Discovery and you decide whether to proceed. Run is optional.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Two weeks of structured discovery: workflow walk-through, system inventory, decision-owner mapping, baseline KPI capture, risk register. Output: a fixed-scope statement of work for Build.
Phase 2 · Weeks 2–4
Design
We translate the Discovery findings into an architecture: which data sources, which prompts, which review queues, which controls, which dashboards. The Build phase ships against this design.
Phase 3 · Weeks 4–8
Build
End of Build deliverables: the production workflow, the operating runbook, the eval pipeline as code, the reviewer interface, the audit log architecture, the dashboard with KPI tracking. All six are inspectable.
Phase 4 · Weeks 8+
Run
We run the workflow with you weekly, expand into adjacent work, and report against baseline.
Interactive ROI calculator
Estimate your AI-native ROI for document processing
Reference inputs below are typical for biotechnology teams in the operations cluster. Adjust them to match your situation.
Projected
Current monthly cost
$56,000
AI-native monthly cost
$18,520
Annual savings
$449,760
67% cost reduction · ~2,601 operator-hours freed / month
Governance and risk controls
Risk in biotechnology comes from three failure modes: the model is wrong, the source data is wrong, or the workflow allows the wrong action. We design for each mode separately — evaluation harness for model error, source curation and freshness for data error, allow-listed tool calls and approval queues for action error. Each has a defined owner and a measurable SLA.
How we report ROI
ROI on document processing shows up in two timeframes for biotechnology: immediate (cycle time, throughput, error rate — visible within 30 days of Run) and structural (operating model maturity, knowledge capture, team capacity unlock — visible at 6-12 months). The first justifies the engagement; the second is what changes the business.
Selected portfolio
Real builds — document processing in biotechnology and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with document processing in biotechnology or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q3 2025
Radiology workflow application — case handling and reporting
Medical imaging operator · Europe
Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access.
- Web app + secure storage
- Structured reporting
- Audit-trail compliance
Q1 → Q2 2026
National legal marketplace — directory, bookings, legal tools, emergency contacts
Government-licensed legal services platform · GCC region
Ministry-licensed bilingual EN/AR platform: directory of certified lawyers, firms, mediators and arbitrators; multi-channel appointment booking (video, phone, in-office); free legal tools (court fees, deadlines, legal interest); police directory with map + hotlines; provider verification workspace; PDF document generation with QR-coded provenance.
- Next.js 16 monorepo (Turborepo)
- Bilingual EN/AR (next-intl)
- Postmark + Web Push
Q4 2025 → Q1 2026
Owners-association management SaaS — 55+ screens, 47 normalized tables
Mid-market property operator · GCC region
Full operational backbone for a property operator running multiple owners associations: properties, units, owners, accounting, service charges, budgets, maintenance, violations, and a resident-facing community portal — replacing a patchwork of spreadsheets and disconnected accounting tools.
- Next.js + tRPC
- PostgreSQL · Drizzle ORM
- JWT federated identity
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native document processing engagements in biotechnology contexts.
Edge cases break the prod thin slice
AI handles 80% but the 20% long tail still floods the human queue
Discovery captures the edge-case taxonomy; Build allocates 30% of effort to the edge-case router
Defensible delivery in a regulated environment
Biotechnology regulatory expectations on AI have hardened over the last twenty-four months. Supervisors who would once accept "we use AI in this workflow" as a sufficient disclosure now ask for the model card, the validation evidence, the override path, and the customer-disclosure language. Vendors who built for the looser bar are scrambling. We built for the harder bar from the start, because the engagement model we sell biotechnology teams is one we can defend in front of any reasonable supervisor.
For document processing, that defense rests on five artefacts the Build phase produces. The model card documents the deployed system: what it does, what it does not do, the training data lineage, the evaluation methodology, the known failure modes. The validation evidence is the labelled test set with its full provenance, the periodic eval reports, and the calibration curves. The override path is documented in the operator playbook and instrumented in the reviewer UI. The customer-disclosure language is drafted with your legal team during Build and tested with sample interactions before launch. The control map ties each control to a named owner and a measurable SLA.
The artefacts live in version control alongside the code, not in a shared drive. They are reviewed quarterly during Run and updated when the system changes. When a supervisor asks for them, the export is a single command. This is not theatre — it is the operating posture that lets your team say "yes, we use AI in this workflow, and here is the evidence we run it responsibly", with the evidence available in the time it takes to brew coffee.
Biotechnology sits inside a regulatory perimeter that an AI-native workflow has to inhabit, not bolt onto afterwards. For document processing, the perimeter includes: data residency rules for the source corpus, model-output traceability for any decision affecting a customer, replayability for the regulator's audit window, and named human accountability for every category of decision. We capture each of those requirements during Discovery, before any code is written, and the Build statement of work names which control implements which requirement. The output is an architecture where compliance is not a phase — it is a layer that lives in the same dashboard as the operating metrics.
The specific controls we ship for biotechnology engagements track the published expectations of the relevant supervisory bodies. The model registry records every prompt and model version that touched a decision, with an immutable hash. The retrieval index documents source provenance, freshness, and approval status per document. The reviewer queue captures the human owner, the timestamp, and the rationale for every escalation. The attestation pack — exportable on demand — bundles the above for any 30/60/90-day window the regulator chooses. This is the same shape that internal audit teams in biotechnology have been refining for a decade; we replicate it inside the AI-native operating layer instead of duplicating it in a separate evidence binder.
Where we depart from a traditional risk-and-controls program is in cadence. The classic posture treats compliance as an annual or quarterly attestation; the AI-native posture treats it as a weekly heartbeat. Every Monday during Run we sample low-confidence decisions, calibrate thresholds, and produce a drift report. Every quarter we run a red-team exercise on the most consequential flows. The compliance officer joining one of those Monday reviews sees the same dashboard the operators see, with attestation-ready evidence one click away. That continuity is what auditors recognize as a controlled environment, and it is what lets biotechnology leadership defend the workflow when the next supervisory examination arrives.
Third-party risk management for AI components in biotechnology is a growing concern that most workflows handle poorly. document processing engagements typically depend on a model provider, a retrieval store, a vector database, sometimes a fine-tuning service. Each is a vendor in your risk register. We map them all during Build, document substitution paths for each, and demonstrate substitutability in the eval harness — so when one vendor changes pricing, terms, or availability, the workflow can move without a re-architecture.
From kickoff to thin-slice production
The first 30 days of Build on document processing for biotechnology follow a deliberate rhythm we have refined over multiple engagements. The pattern is not "deliver the whole workflow then test"; it is "deliver vertical slices, each production-ready, with the next slice scoped from the prior slice's evidence".
Slice 1 (week 1-2): the retrieval and intake layer running against a curated subset of your data, with the labelled test set captured and the eval harness wired up. Outcome: we can prove the system finds the right context for a representative range of biotechnology cases. Slice 2 (week 3-4): the action layer drafting outputs that a reviewer approves before they hit production. Outcome: we can prove the system generates defensible drafts at a measurable accuracy rate. Slice 3 (week 5-6): low-confidence routing live, high-confidence automation gated by a calibration threshold. Outcome: we can prove the throughput-quality tradeoff is favourable on real production traffic. Subsequent slices widen the automation envelope, expand the integration surface, and add the reporting layer.
The vertical-slice cadence is what lets your team see compounding evidence rather than waiting for a big-bang reveal. It also lets us catch architectural issues early — week 2 evaluation results that surprise us are far cheaper to absorb than week 8 results. By the close of Build, every architectural choice has been validated against real biotechnology data, not against a synthetic benchmark.
What the first 30 days actually look like on document processing for biotechnology is rarely communicated in vendor decks — so we describe it concretely here. Kickoff Monday: alignment on the labelled test set methodology, the integration scoping for ELN, the success metric definitions. By Wednesday, an initial 50-case labelled test set is in place, drafted by your operator team and reviewed by our delivery lead. By Friday, the retrieval index has its first batch of approved sources, indexed and queryable.
Week 2 is integration and prompt-strategy week. We connect to ELN, expand the labelled test set to 150+ cases, and ship the first prompt iteration against the harness. The Friday demo shows initial accuracy numbers on the test set — deliberately not impressive yet, but real. Week 3 is the action-layer week: draft generation, reviewer queue UI, audit log instrumentation. Friday demo shows the first end-to-end case flow.
Week 4 is the thin-slice production week. We deploy to a narrow audience (5-10% of routine cases), instrument the operator feedback loop, and run the first weekly performance review with your team. By end of day-30, the workflow is processing real biotechnology traffic with the calibration loop closing, and the next phase of Build is scoped from concrete evidence.
A comparable engagement we have shipped
A comparable engagement worth knowing about for document processing in biotechnology is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Radiology workflow application — case handling and reporting. Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access. (Medical imaging operator · Europe, Q3 2025.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to biotechnology (ELN and the adjacent systems) and the prompt strategy tuned to the document processing vernacular in your category.
For US buyers
US compliance scaffolding for document processing in biotechnology (FDA 21 CFR Part 11, NIST AI RMF)
Biotechnology engagements touching US clients on document processing ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for biotechnology is Electronic Records and Electronic Signatures (FDA 21 CFR Part 11) — addressed below alongside the adjacent frames we encounter.
FDA 21 CFR Part 11
Electronic Records and Electronic Signatures
Authority: U.S. Food and Drug Administration
- Scope
- Validation of electronic records in GxP environments, audit trails, electronic signatures, system access controls.
- How we ship inside it
- Pharma and medical-device engagements include 21 CFR Part 11 system validation documentation: design qualification (DQ), installation qualification (IQ), operational qualification (OQ), performance qualification (PQ). Audit trails are tamper-evident and signature-bound.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
For biotechnology CTOs already running an ML platform, the value we bring is not engineering — it is the operating model and the productized governance stack. We have shipped enough variations of this workflow to know what fails in production, what reviewer queues look like at scale, and what evaluation cadence actually catches drift. Reusable knowledge, not reusable code.
What to ask us before signing
- Ask which subflow we recommend for the first thin-slice and why, given your specific biotechnology context.
- Ask how the integration against ELN is scoped — what is in scope, what is explicitly out, where the boundary sits.
- Ask how prompt versioning is gated — what eval criteria a candidate prompt has to beat to be promoted to production.
- Ask how we report against documents per hour, extraction accuracy, exception rate, and processing cost and how often the reports land on leadership's desk.
- Ask what the Run handover looks like — when does your team take operational ownership and what stays with us.
Recommended first project
Our recommendation for a first document processing engagement in biotechnology is to pick the slice of the workflow that satisfies four criteria: there is a measurable baseline, the work is genuinely repetitive, the failure mode is reversible within a reasonable window, and a senior operator on your team can be the first reviewer. Those four criteria filter out the engagements that look impressive in a slide and fail in week three. The 90-day target is "thin slice in production with a defended baseline". By day 30, the system processes a small share of real traffic with full reviewer oversight. By day 60, the share has widened and the calibration is data-driven. By day 90, the operating cadence is your team's, the dashboard reflects empirical performance, and the case for the next workflow writes itself.
Frequently asked questions
How do you automate document processing in biotechnology with AI?+
Discovery starts with a workflow walk-through and a labelled test set captured from real biotechnology cases. Build delivers the AI layer in vertical slices — intake, retrieval, action, review — each gated by the eval harness. Run operates the workflow against documents per hour, extraction accuracy, exception rate, and processing cost with a weekly cadence and a quarterly architecture review. The integration footprint covers ELN and LIMS.
What does it cost to automate document processing for biotechnology teams?+
Discovery → Build → Run, each a separate commercial envelope. Discovery: $6k for 2-week sprint. Build: $20k–$28k for 6-10 weeks, scoped against the Discovery output. Run: $2.5k–$4k / mo per month, month-to-month, no lock-in.
What is the best AI agent for document processing in biotechnology?+
For biotechnology document processing, the operating stack we ship combines a frontier LLM with grounded retrieval, tool-use for ELN integration, and a calibrated reviewer queue. Model choice is treated as a substitutable layer — the architecture survives provider changes — so you are not committed to a vendor that may change pricing or terms in 18 months.
How long does it take to deploy AI document processing for biotechnology?+
Two weeks of Discovery, six to ten weeks of Build, then optional Run. Production thin-slice traffic by week 6-8. Full operating envelope by week 10-12. By day 90, the dashboard reports documents per hour, extraction accuracy, exception rate, and processing cost against the baseline captured in Discovery, and leadership has the empirical record to defend expansion.
What do we own, and what do you own?+
Our team owns delivery and operations of the AI layer (prompts, retrieval, evaluation, audit log, reviewer queue, weekly cadence). Your biotech founders, clinical operations teams, business development leaders, and scientific program managers team owns the policy decisions, the source curation, the exception handling on cases the system routes for human judgment, and the commercial decisions tied to the workflow. The boundary is encoded in the engagement contract; the artefacts are handed over progressively across Build and Run.
What's the operating cadence during Run?+
Monday metric review, Wednesday prompt and retrieval refresh, Friday calibration audit. The cadence is the deliverable; the prompts are the artefacts that change between cycles. Quarterly architecture retrospective. The cadence is documented and absorbable by your operator team progressively during the first quarter of Run.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
documents per hour, extraction accuracy, exception rate, and processing cost measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with ELN and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on biotechnology engagements. Cited here so you can verify and dig deeper.
- NIH Artificial Intelligence
- Worldwide AI and Generative AI Spending Guide — IDC
- Hype Cycle for Artificial Intelligence — Gartner
- Future of Work: Operations — Deloitte Insights
- Lighthouse Network — Operations AI Adoption — World Economic Forum + McKinsey
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
Concepts on this page:
AI workflow·Thin slice·Reviewer queue·Evaluation harness·Tool use·Audit logFull glossary →High-intent reads
Start the engagement
Start a Biotechnology engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.