Commerce · Revenue & Growth
Content Marketing Automation for Retail, Built AI-Native
Engagement details for retail executives, ecommerce leaders, merchandising teams, and store operations on content marketing: phased pricing, expected timeline, the controls we ship by default, the KPIs we baseline during Discovery and report against during Run.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native content marketing for retail — Three-phase delivery: scoped Discovery, fixed-price Build, opt-in Run. Built for retail operating reality, shipped against a measurable baseline, governed under the same controls your auditors expect. Expected delta on organic pipeline: +50%.
Key facts
- Industry
- Retail
- Use case
- Content Marketing
- Intent cluster
- Revenue & Growth
- Primary KPI
- organic pipeline, publication cadence, content refresh rate, and assisted conversions
- Top benchmark
- Pipeline conversion (SQL → opportunity): 18% → 27% (+50%)
- Systems integrated
- commerce platforms, PIM, ERP
- Buyer
- retail executives, ecommerce leaders, merchandising teams, and store operations
- Risk lens
- pricing errors, brand consistency, consumer privacy, stockouts, and marketplace compliance
- Engagement timeline
- Discovery 2 weeks → Build 6 weeks → Run continuous
- Team size
- 1 senior delivery + founder oversight
- Discovery price
- $5k · 2-week sprint
- Build price
- $15k–$22k · 6-8 weeks
Primary outcome
publish better expert content at a higher cadence
What we ship
editorial operating system, briefing templates, review workflows, and distribution calendar
KPIs we report on
organic pipeline, publication cadence, content refresh rate, and assisted conversions
Why Retail teams hire us for this
Retail buyers we talk to share a common frustration: too many AI vendor demos, too few production deployments that survive a quarterly review. AI-native content marketing is the answer to that gap — every engagement we ship is designed to pass a CFO's challenge, a risk officer's review, and an operator's daily use, simultaneously.
Across retail sales orgs we have benchmarked, the conversion floor from MQL to SQL hovers around 12-18% — most of the leakage happens at first-touch quality. That is the layer AI-native systems compress fastest.
Industry context: Retail operates with razor-thin per-SKU margins (4-9% typical) and complex inventory dynamics across 5k-50k SKUs per banner. Personalization AI must respect CCPA/GDPR consent + state-level data minimization rules.
Benchmarks we hit
Reference benchmarks from production deployments of content marketing in retail-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Pipeline conversion (SQL → opportunity) Lift attributed to better intent scoring + faster handoff from AI to AE | 18% | 27% | +50% |
Cost per qualified meeting Includes AI infra cost, SDR time, and overhead allocation | $420 | $95 | −77% |
Lead-to-meeting cycle time Median across Salesforce-reporting B2B teams; AI-native compression validated on first thin-slice deployment | 11.4 days | 2.8 days | −75% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
The hardest part of AI-native content marketing is not the LLM call — it is mapping the current process, finding where judgment is required, identifying which decisions need evidence, and separating high-confidence automation from cases that need human approval. We dedicate the full Discovery sprint to that mapping before any code is written.
What we build inside the workflow
The hardest engineering question in Build for content marketing in retail is not the prompt or the model — it is the data access layer. We spend Discovery on identifying which sources the workflow actually needs, which are reachable through clean APIs, which need ETL, which have permission issues, which carry latency or freshness constraints. The Build statement of work names which sources are in scope and which are explicitly out of scope. The cleanest engagements are the ones where the data access plan is signed off before any code is written.
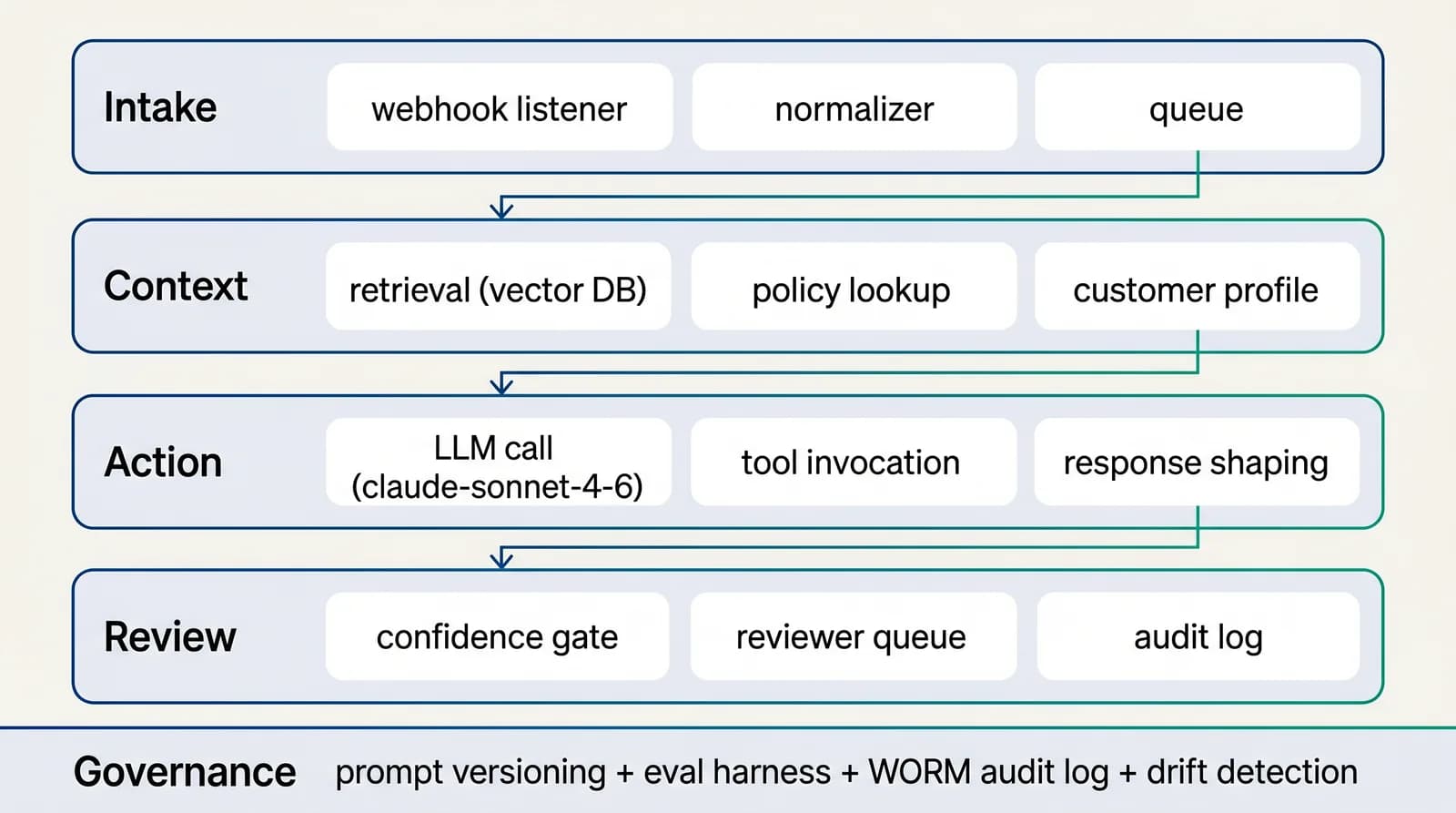
Reference architecture
4-layer AI-native workflow for revenue & growth
The reference architecture treats prompts and retrieval as code: version-controlled, evaluated on every change, deployed through CI. That posture is what makes content marketing legible to engineering audit twelve months in.See the full architecture diagram for Revenue & Growth →
AI-native vs traditional approach
For retail executives, ecommerce leaders, merchandising teams, and store operations who has run the build-vs-buy calculation before: how the AI-native engagement model changes the answer specifically for content marketing, on the dimensions your CFO and your CTO are likely to challenge.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Production launch window | 6-9 months on average | 5-8 weeks thin slice to production |
| Cost structure | Open-ended monthly retainer | Fixed-price per phase, no annual commitment |
| Governance layer | Spreadsheet logs, quarterly attestation | Versioned prompts + queryable audit log + reviewer queue + attestation pack |
| Operator productivity | 1.0× (baseline) | −77% |
| Marginal cost | Baseline operator cost per case | Drops 60-80% on the routine envelope |
| Off-boarding | Hand-over slips, knowledge stays with vendor | Run is month-to-month; artefacts handed over throughout Build |
Traditional merchandising team allocates 35-45% of time to SKU-level decisions; AI-native merchandising compresses this to 8-12%, freeing senior buyers for strategy.
Engagement scope & pricing
The commercial envelope is set at Discovery and held through Build. Run is optional and month-to-month — the exit path is part of the engagement, not a separate negotiation.
Revenue engagement
Fixed prices per phase, no multi-quarter commitments, exit possible at every phase boundary.
Phase 1 · Discovery
$5k
2-week sprint
Phase 2 · Build
$15k–$22k
6-8 weeks
Phase 3 · Run
$2k–$3k / mo
optional, hourly bank also available
~$25k–$45k typical year 1 (60% take the run option for ~6 months)
Outbound, growth, or revenue-ops workflow, integration with your CRM, weekly operating review during Run.
Discovery contains its own value (the workflow map, the baseline, the SoW). You can stop after Discovery and still own the artefacts. If you proceed, Build is fixed-scope and fixed-price.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Discovery is short, intense, and decision-producing. By end of week 2, you have the workflow map, the baseline, the SoW, and the risk register. No code yet — the next phase is calibrated against this evidence.
Phase 2 · Weeks 2–4
Design
Design phase is where the irreversible architectural choices are made: layer boundaries, substitution interfaces, governance posture, evaluation methodology. We invest disproportionately here because corrections in Build are 10× more expensive.
Phase 3 · Weeks 4–8
Build
Vertical-slice delivery against the labelled test set. Each slice ships to production, gated by eval criteria. By end of Build, the workflow is operating on real traffic with the calibration discipline established.
Phase 4 · Weeks 8+
Run
Run cadence is calibrated to your operational reality: weekly metric review, bi-weekly prompt refresh, monthly calibration audit, quarterly architecture review. The Run phase compounds value as the labelled test set grows.
Interactive ROI calculator
Estimate your AI-native ROI for content marketing
Reference inputs below are typical for retail teams in the revenue cluster. Adjust them to match your situation.
Projected
Current monthly cost
$24,000
AI-native monthly cost
$7,920
Annual savings
$192,960
67% cost reduction · ~468 operator-hours freed / month
Governance and risk controls
Retail regulators and internal auditors care about three things: where did the data come from, who approved the decision, and can it be replayed? Our control stack answers all three. Approved source list, signed reviewer log, replayable prompt + model + retrieval bundle. That stack is non-negotiable on every engagement we ship.
How we report ROI
The expensive mistake in retail ROI accounting is to attribute productivity gains to AI when they came from the process redesign that surrounded the build. We split the attribution explicitly: how much came from automation, how much from cleaner workflow definition, how much from better instrumentation. That honesty is what lets leadership trust the next phase of investment.
Selected portfolio
Real builds — content marketing in retail and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with content marketing in retail or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q1 2026
Premium marketing site for a specialist detailing workshop
Premium vehicle care specialist · DACH region
Marketing site for a premium vehicle detailing workshop: ceramic coating, paint protection film, detailing, smart repair. Luxury automotive visual direction, structured per-service catalog with proof points, German-market SEO foundation, appointment-oriented CTAs throughout the funnel.
- Next.js + custom design system
- Core Web Vitals first
- German-market SEO
Q1 2026
AI-powered interior design platform — generative room concepts for the MEA market
AI interior design SaaS · MEA region
Vertical AI SaaS for interior design in the Middle East: image-conditioned generation tuned for local taste profiles, room-by-room concept workflow, project export for designers and clients. Built with a market-specific dataset and an evaluation loop on regional aesthetic baselines.
- Next.js + image generation pipeline
- Regional taste-profile tuning
- Designer + client export flows
Q3 2025
Specialist automotive software-optimization site — multi-brand chiptuning
Vehicle optimization specialist · DACH region
Marketing site for an automotive software-optimization specialist serving multiple regions: brand-by-brand service architecture, technical service descriptions accessible to non-technical buyers, lead capture per service, regional-catchment SEO foundation.
- Next.js + responsive
- Multi-brand IA
- Regional SEO
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native content marketing engagements in retail contexts.
CRM hygiene degrading after launch
AI writes to CRM faster than humans validate; data quality drops after week 6
Confidence-scored writes with auto-rollback below threshold + weekly data-quality dashboard
Designing for the consumer scale of this category
The brand voice on content marketing in retail is a strategic asset that drifts measurably when the workflow is under stress. We engineer against that drift with three controls: the editorial voice guide lives in version control and is read by the prompt layer at every inference call; the weekly review samples outputs across the voice spectrum (warm, formal, urgent, playful) to detect calibration shift; the operator team can flag any output that violates voice within the reviewer interface, with the flag feeding the next iteration. Brand voice becomes a measurable property rather than an aspirational one.
The consumer in retail arrives at a workflow with three implicit expectations: speed (sub-second on the routine), recognition (the system remembers what they told it last time), and recourse (a fast and obvious path to a human if the automation gets it wrong). AI-native delivery on content marketing engineers all three deliberately; the alternative is to deliver one or two and quietly disappoint on the others.
Speed comes from inference-path design. The high-confidence path is sub-second because the prompt is tight, the retrieval index is warm, the model is the right size for the task, and the routing logic is instrumented. The lower-confidence path is slower by design — the reviewer needs the time — but the customer experience is communicated honestly ("a specialist will respond within X") instead of awkwardly automated. The split is data-driven, not assumed.
Recognition comes from the retrieval layer. A returning customer in retail should not feel like a new customer; the system has their history, their preferences, their prior interactions. We model the retrieval index around the customer entity for content marketing engagements, with privacy-aware filters and explicit consent boundaries. The result is a workflow that feels personal without becoming creepy — the line is in the consent model, which is drafted with your legal team during Build.
Recourse comes from the escalation surface. The customer who hits a wall with the automation must see the path to a human within one click, with the context they have already shared preserved across the handoff. The failure mode we explicitly engineer against is the one where the automation answers a question the customer did not ask, then asks them to restart with a human. The cost of that pattern is invisible in the dashboard for two months and visible in the churn report at quarter end. We instrument against it from day one of Run.
What actually happens in the first month
What the first 30 days actually look like on content marketing for retail is rarely communicated in vendor decks — so we describe it concretely here. Kickoff Monday: alignment on the labelled test set methodology, the integration scoping for commerce platforms, the success metric definitions. By Wednesday, an initial 50-case labelled test set is in place, drafted by your operator team and reviewed by our delivery lead. By Friday, the retrieval index has its first batch of approved sources, indexed and queryable.
Week 2 is integration and prompt-strategy week. We connect to commerce platforms, expand the labelled test set to 150+ cases, and ship the first prompt iteration against the harness. The Friday demo shows initial accuracy numbers on the test set — deliberately not impressive yet, but real. Week 3 is the action-layer week: draft generation, reviewer queue UI, audit log instrumentation. Friday demo shows the first end-to-end case flow.
Week 4 is the thin-slice production week. We deploy to a narrow audience (5-10% of routine cases), instrument the operator feedback loop, and run the first weekly performance review with your team. By end of day-30, the workflow is processing real retail traffic with the calibration loop closing, and the next phase of Build is scoped from concrete evidence.
Recent build that maps to this engagement
The recent build in our portfolio that maps cleanest to content marketing in retail is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
AI-powered interior design platform — generative room concepts for the MEA market. Vertical AI SaaS for interior design in the Middle East: image-conditioned generation tuned for local taste profiles, room-by-room concept workflow, project export for designers and clients. Built with a market-specific dataset and an evaluation loop on regional aesthetic baselines. (AI interior design SaaS · MEA region, Q1 2026.)
The reason that engagement is a useful reference is not the surface match — it is the underlying decision structure. The same questions show up on content marketing for retail: where to draw the automation boundary, how to calibrate confidence thresholds against the labelled test set, what to put in the reviewer UI, how to instrument drift. The answers transfer; the implementation specifics adapt to your stack.
For US buyers
US compliance scaffolding for content marketing in retail (CCPA / CPRA, PCI DSS, FTC Act §5)
Retail engagements touching US clients on content marketing ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for retail is California Consumer Privacy Act / California Privacy Rights Act (CCPA / CPRA) — addressed below alongside the adjacent frames we encounter.
CCPA / CPRA
California Consumer Privacy Act / California Privacy Rights Act
Authority: California Privacy Protection Agency (CPPA)
- Scope
- California resident data rights (access, deletion, opt-out of sale/sharing), sensitive personal information, automated decision-making opt-out (proposed regs).
- How we ship inside it
- California-touching engagements ship with consumer-rights workflows: access request handling, deletion within 45 days, opt-out signals (GPC) honored at the retrieval layer. Automated-decision-making disclosures align with proposed CPPA regulations.
PCI DSS
Payment Card Industry Data Security Standard
Authority: PCI Security Standards Council
- Scope
- Cardholder data protection, network security, vulnerability management, access control, monitoring.
- How we ship inside it
- We do not store PAN. Card data is tokenised via your existing PCI-validated payment processor (Stripe, Adyen, Braintree). AI workflows touching cardholder environments stay outside the CDE boundary by design.
FTC Act §5
Federal Trade Commission Act, Section 5
Authority: U.S. Federal Trade Commission
- Scope
- Unfair or deceptive acts or practices, AI/algorithmic transparency, substantiation of marketing claims, recent FTC guidance on AI claims.
- How we ship inside it
- AI-generated marketing copy passes through a claims-substantiation reviewer queue before publication. We follow FTC guidance on AI/algorithmic transparency: no false claims about model capability, no deceptive personalisation, no covert AI-generated reviews.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
The strongest pattern we see in retail is blended: we design and launch the first production workflow, your internal team owns data access, security review, and stakeholder alignment. Over 6-12 months, your team takes over Run while we move to the next workflow. The exit plan is part of the Statement of Work.
What to ask us before signing
- Ask which subflow we recommend for the first thin-slice and why, given your specific retail context.
- Ask how the integration against commerce platforms is scoped — what is in scope, what is explicitly out, where the boundary sits.
- Ask how prompt versioning is gated — what eval criteria a candidate prompt has to beat to be promoted to production.
- Ask how we report against organic pipeline, publication cadence, content refresh rate, and assisted conversions and how often the reports land on leadership's desk.
- Ask what the Run handover looks like — when does your team take operational ownership and what stays with us.
Recommended first project
The first project we recommend for retail on content marketing is rarely the one leadership names in the initial conversation. The named project is usually the most politically visible — which is also the riskiest place to ship a first AI-native workflow. We typically recommend the adjacent subflow with the cleanest baseline, the smallest blast radius, and the most repetitive operator work. That first project produces three artefacts that the visible project needs: a labelled test set the operator team has signed off on, a reference architecture against commerce platforms, and a credibility track record with the internal stakeholders who will be asked to support the second engagement. By the time we propose the second workflow — the visible one — the organisational gravity is on our side.
Frequently asked questions
How do you automate content marketing in retail with AI?+
Discovery starts with a workflow walk-through and a labelled test set captured from real retail cases. Build delivers the AI layer in vertical slices — intake, retrieval, action, review — each gated by the eval harness. Run operates the workflow against organic pipeline, publication cadence, content refresh rate, and assisted conversions with a weekly cadence and a quarterly architecture review. The integration footprint covers commerce platforms and PIM.
What does it cost to automate content marketing for retail teams?+
Discovery → Build → Run, each a separate commercial envelope. Discovery: $5k for 2-week sprint. Build: $15k–$22k for 6-8 weeks, scoped against the Discovery output. Run: $2k–$3k / mo per month, month-to-month, no lock-in.
What is the best AI agent for content marketing in retail?+
For retail content marketing, the operating stack we ship combines a frontier LLM with grounded retrieval, tool-use for commerce platforms integration, and a calibrated reviewer queue. Model choice is treated as a substitutable layer — the architecture survives provider changes — so you are not committed to a vendor that may change pricing or terms in 18 months.
How long does it take to deploy AI content marketing for retail?+
Two weeks of Discovery, six to ten weeks of Build, then optional Run. Production thin-slice traffic by week 6-8. Full operating envelope by week 10-12. By day 90, the dashboard reports organic pipeline, publication cadence, content refresh rate, and assisted conversions against the baseline captured in Discovery, and leadership has the empirical record to defend expansion.
What do we own, and what do you own?+
Our team owns delivery and operations of the AI layer (prompts, retrieval, evaluation, audit log, reviewer queue, weekly cadence). Your retail executives, ecommerce leaders, merchandising teams, and store operations team owns the policy decisions, the source curation, the exception handling on cases the system routes for human judgment, and the commercial decisions tied to the workflow. The boundary is encoded in the engagement contract; the artefacts are handed over progressively across Build and Run.
How do you measure revenue impact for content marketing in retail?+
We instrument organic pipeline, publication cadence, content refresh rate, and assisted conversions from day one, paired with sector-level metrics such as conversion rate, inventory turns, gross margin, return rate, and customer lifetime value. We report against baseline weekly during Run, and we publish a 90-day impact recap.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
organic pipeline, publication cadence, content refresh rate, and assisted conversions measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with commerce platforms and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on retail engagements. Cited here so you can verify and dig deeper.
- National Retail Federation
- The State of AI — McKinsey & Company
- Build for the Future: AI Maturity Survey — BCG
- State of Sales Report — Salesforce Research
- B2B Buying Disconnect: Buying Decisions are Made Without Sellers — Forrester
- State of Retail Report — National Retail Federation
- Retail Industry AI Adoption — Deloitte Retail Industry
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Retail engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.