Public and Social Impact · Knowledge & Insight
Executive Reporting for Nonprofits: An AI-Native Insight System
A scoped engagement page for nonprofit executives, fundraising teams, program operators, and grant managers evaluating executive reporting. We cover deliverables, timeline, pricing, controls, and the reporting cadence we run during the Build and optional Run phases.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native executive reporting for nonprofits — Fixed-price phases that take executive reporting from a Discovery baseline to a production thin slice on real nonprofits traffic, with the operating cadence handed over to your team by the end of Build. Expected delta on reporting cycle time: −94%.
Key facts
- Industry
- Nonprofits
- Use case
- Executive Reporting
- Intent cluster
- Knowledge & Insight
- Primary KPI
- reporting cycle time, decision clarity, follow-through, and executive alignment
- Top benchmark
- Time-to-insight (analyst query → answer): 3.2 hours → 11 minutes (−94%)
- Systems integrated
- donor CRM, grant management, email platforms
- Buyer
- nonprofit executives, fundraising teams, program operators, and grant managers
- Risk lens
- donor privacy, beneficiary dignity, grant compliance, message accuracy, and trust
- Engagement timeline
- Discovery 2.5 weeks → Build 7 weeks → Run continuous
- Team size
- 2 senior delivery (1 architect + 1 implementer)
- Discovery price
- $6k · 2-week sprint
- Build price
- $22k–$30k · 7-10 weeks
Primary outcome
give leadership clearer operating visibility with less manual reporting
What we ship
board reporting assistant, KPI narratives, risk register, and operating review pack
KPIs we report on
reporting cycle time, decision clarity, follow-through, and executive alignment
Why Nonprofits teams hire us for this
Nonprofits teams running a successful executive reporting program share a posture: they treat the workflow as a long-lived production system, not as a marketing-grade initiative. The KPI dashboard is live by week six, the audit log is queryable by week eight, the operator playbook is hand-over-able by week ten. That posture is built into the engagement contract — not as language but as deliverables.
Foundational RAG research (Lewis et al., 2020) and follow-up work on long-context limitations (Liu et al., 2023) inform how we architect retrieval for nonprofits: hybrid search + reranking + grounded citations, not raw long-context dumping.
Industry context: Mid-market and enterprise operators face the same fundamental tradeoff: AI must compress operational cycle time while remaining auditable and integrable with existing systems of record.
Benchmarks we hit
Reference benchmarks from production deployments of executive reporting in nonprofits-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Time-to-insight (analyst query → answer) Source-grounded retrieval + structured output; analyst validates rather than searches | 3.2 hours | 11 minutes | −94% |
Knowledge freshness (median age cited) Auto-refresh of approved sources + freshness scoring on retrieval | 94 days | 12 days | −87% |
Repeated-question volume AI surfaces existing answers + flags content gaps for SME refresh | 100% (baseline) | 44% | −56% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
The cadence we run on executive reporting for nonprofits is deliberately boring. Monday: pull the metric report against the labelled test set, sample the cases the system was uncertain about, review the reviewer queue calibration. Wednesday: refresh the retrieval index from approved sources, deploy any new prompt versions that beat incumbents on eval, run regression on the test set. Friday: walk through the operator feedback from the week, fold patterns into the playbook, scope the next iteration. Boring is the point — heroic operating cadences do not survive six months.
What we build inside the workflow
The visible deliverable of a Build engagement for executive reporting is the working workflow: board reporting assistant, KPI narratives, risk register, and operating review pack. The invisible deliverables — labelled test set, prompt repository, evaluation harness, audit log infrastructure, runbook, exit plan — are what makes the workflow defensible 6 and 12 months later. We document and hand over all of them at the close of Build.
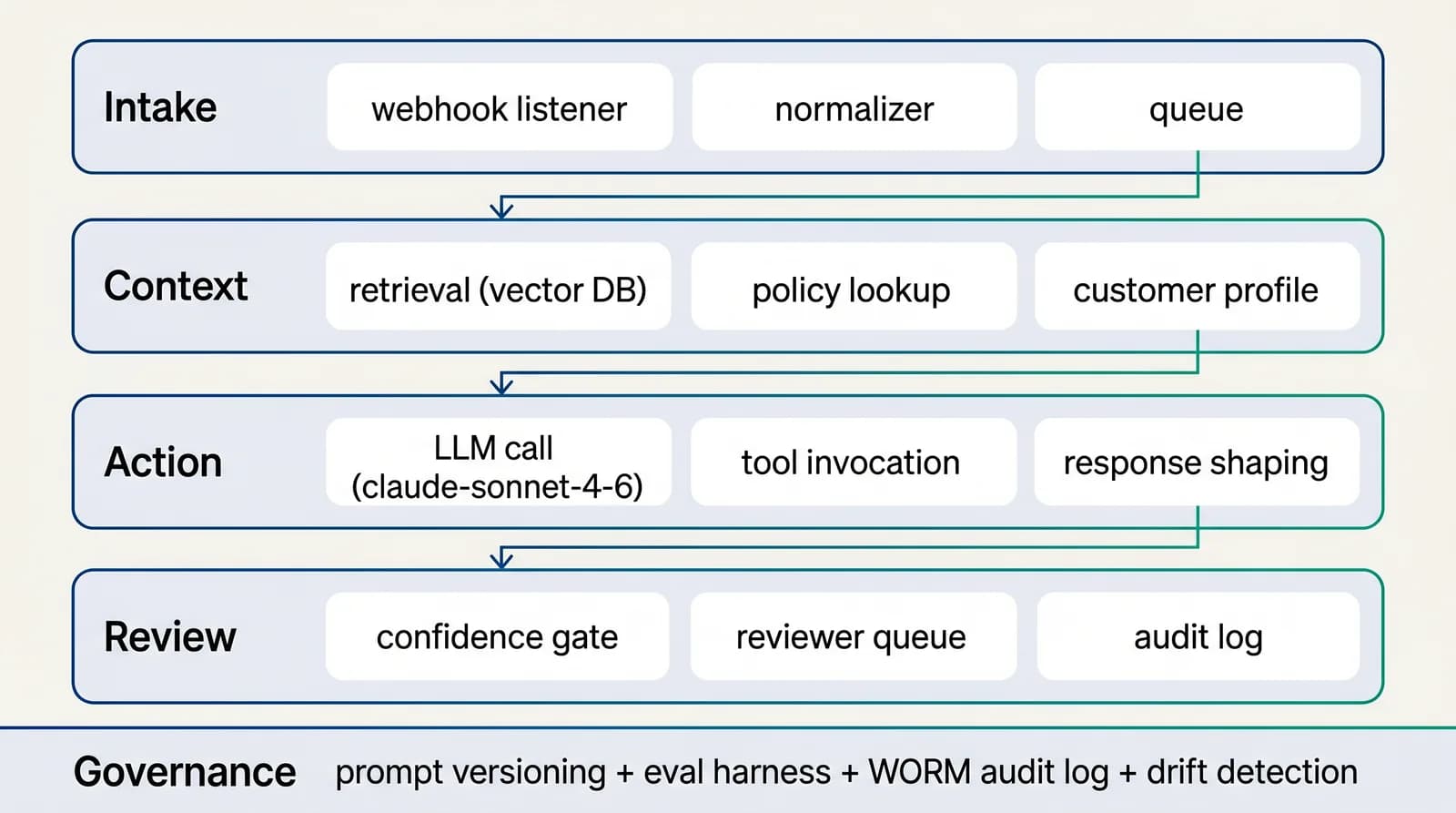
Reference architecture
4-layer AI-native workflow for knowledge & insight
Four layers, in the order data flows through them: intake (classify and tag), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases). Each layer is independently observable.See the full architecture diagram for Knowledge & Insight →
AI-native vs traditional approach
Nonprofits teams considering executive reporting typically weigh four paths: in-house build with new hires, BPO contract, generic AI SaaS, or AI-native engagement. The table below compares the trade-offs.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Time-to-first-traffic | Multi-quarter program | 8-week thin-slice ship target |
| Commercial structure | Monthly retainer with FTE assumptions | Discovery, Build, Run priced independently |
| Control surface | Manual audit cycles | Versioned artefacts, signed audit log, named owners per control |
| Throughput-per-FTE | 1.0× (baseline) | −87% |
| Unit economics | Unchanged from baseline | 60-80% lower on routine cases |
| Termination clause | Multi-quarter notice; documentation gaps | Month-to-month Run; handover plan in Build SoW |
Traditional process automation projects cost $80-200k+ with 6-12 month payback; AI-native engagements deliver thin-slice production in 6-8 weeks with measurable baseline-vs-actuals reporting.
Engagement scope & pricing
Phased and fixed-price by default. You commit one phase at a time, with a defined deliverable per phase.
Insight engagement
Discovery → Build → Run, each phase committable on its own. No bundling, no annual minimum.
Phase 1 · Discovery
$6k
2-week sprint
Phase 2 · Build
$22k–$30k
7-10 weeks
Phase 3 · Run
$3k–$5k / mo
optional, hourly bank also available
~$34k–$60k typical year 1 (60% take the run option for ~6 months)
Source curation, retrieval architecture, evaluation harness, and decision dashboards.
Start with Discovery; nothing more is required to begin. Build is scoped from the Discovery output. Run, if it happens, is month-to-month with no lock-in.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Two weeks of structured discovery: workflow walk-through, system inventory, decision-owner mapping, baseline KPI capture, risk register. Output: a fixed-scope statement of work for Build.
Phase 2 · Weeks 2–4
Design
We translate the Discovery findings into an architecture: which data sources, which prompts, which review queues, which controls, which dashboards. The Build phase ships against this design.
Phase 3 · Weeks 4–8
Build
Vertical-slice delivery against the labelled test set. Each slice ships to production, gated by eval criteria. By end of Build, the workflow is operating on real traffic with the calibration discipline established.
Phase 4 · Weeks 8+
Run
Optional Run phase, month-to-month, no lock-in. Weekly performance review against the Discovery baseline. Quarterly architecture retrospective. The cadence is documented; your team can absorb it any time.
Interactive ROI calculator
Estimate your AI-native ROI for executive reporting
Reference inputs below are typical for nonprofits teams in the knowledge insight cluster. Adjust them to match your situation.
Projected
Current monthly cost
$26,400
AI-native monthly cost
$6,684
Annual savings
$236,592
75% cost reduction · ~1,672 operator-hours freed / month
Governance and risk controls
Internal auditors and external regulators in nonprofits converge on the same three questions: data provenance, decision traceability, replayability. Our control stack answers all three from the same audit log — one source of truth, queryable, exportable, signed. No spreadsheet reconciliation, no after-the-fact narrative.
How we report ROI
The business case lives in operating metrics, not model benchmarks. For executive reporting, the metrics that matter are reporting cycle time, decision clarity, follow-through, and executive alignment. For Nonprofits, leadership will also care about donor retention, grant cycle time, program reporting effort, and cost per dollar raised. Every build decision we make connects to one of those metrics, and we publish a weekly performance review during the Run phase.
Selected portfolio
Real builds — executive reporting in nonprofits and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with executive reporting in nonprofits or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q2 2026
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual
Mid-market property operator · GCC region
Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one.
- Next.js + tRPC
- Per-unit auth + audit trail
- Bilingual EN/AR (next-intl)
Q1 2026
AI pricing system for startup founders — 9-step foundation + personalised AI brain
Founder-led pricing-strategy AI SaaS · DACH
First AI-powered pricing platform for startup founders. Structured 9-step pricing-foundation flow (product, customers, competition, costs, boundaries, model, strategy), personalised AI brain that learns from each business over time, two subscription tiers with money-back guarantee. Built end-to-end including billing, AI orchestration, and onboarding.
- Next.js + TypeScript
- Multi-LLM orchestration
- Subscription billing
Q3 2025
On-demand regional aviation booking — flexible flight network across smaller cities
Regional aviation operator · DACH
Booking and operations stack for an on-demand regional aviation network connecting secondary cities. Customer-facing booking flow with dynamic availability, operator-side dispatch tools, route economics dashboards. Designed for a sustainable flight-network operating model rather than fixed-schedule airline patterns.
- Next.js + native-app companion
- Dynamic availability engine
- Operator dispatch console
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native executive reporting engagements in nonprofits contexts.
Stale corpus, current answers
Sources indexed in February, AI confidently cites them in October as 'current'
Freshness scoring on every retrieval; flag stale citations + auto-trigger SME refresh workflow
From kickoff to thin-slice production
For nonprofits engagements on executive reporting, the first 30 days are not about building features — they are about producing the labelled test set that will govern every subsequent decision. The test set is the most valuable artefact of the engagement, because it is what makes "did this change make the workflow better?" a measurable question instead of an opinion.
We spend week 1 on test-set capture. The operator team picks 200-400 representative cases spanning routine, exceptional, ambiguous, and adversarial. Each case has the expected outcome, the expected reasoning, and the source citations a reviewer would want to see. The test set is reviewed for coverage gaps, signed off by the engagement sponsor, and version-controlled alongside the prompts.
From week 2, every prompt change, retrieval-index update, and threshold calibration is gated by the eval harness running against this test set. Improvements that beat the incumbent across enough metric slices get promoted; changes that look impressive on one slice but regress on another are flagged for review. By the end of Build, the test set has grown to 600-1000 cases, the workflow has been through 15-25 eval cycles, and nonprofits leadership has empirical evidence that the system performs on their data, not on a vendor's demo.
This is the practice most nonprofits AI projects skip because it looks like overhead in the first three weeks. It is the practice that determines whether the workflow survives the third quarter of Run, which is why we treat it as the foundation of Build rather than an afterthought.
If you have ever shipped a non-trivial production system you know the first 30 days are make-or-break. For executive reporting in nonprofits, the make-or-break decisions are: what does the labelled test set look like, what is in scope for the integration against donor CRM, where does the automation boundary sit, and how is the reviewer queue UX going to feel to your operator team. We answer all four in the first two weeks.
Labelled test set: 200 cases minimum by end of week 2, signed off by the engagement sponsor, covering routine, exceptional, ambiguous, and adversarial. Integration scope: documented and bounded by end of week 1, with the data-access plan reviewed by your engineering team. Automation boundary: drawn deliberately in week 2 — full automation lane, drafted-with-review lane, reserved-to-human lane — with confidence thresholds calibrated against the test set. Reviewer UX: prototyped in week 2 with two of your senior operators in the loop, iterated through week 3.
From day 30, the Build sprint shifts to widening the envelope. The decisions made in the first month are the ones that shape the next 12 months of operating the workflow — which is why we resist the temptation to skip ahead to the model layer before the test set and the reviewer UX have been earned.
A comparable engagement we have shipped
The closest pattern reference we ship for executive reporting in nonprofits is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual. Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one. (Mid-market property operator · GCC region, Q2 2026.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to nonprofits (donor CRM and the adjacent systems) and the prompt strategy tuned to the executive reporting vernacular in your category.
For US buyers
US compliance scaffolding for executive reporting in nonprofits (NIST AI RMF)
Nonprofits engagements touching US clients on executive reporting ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for nonprofits is NIST AI Risk Management Framework (AI 100-1) (NIST AI RMF) — addressed below alongside the adjacent frames we encounter.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
For nonprofits CTOs already running an ML platform, the value we bring is not engineering — it is the operating model and the productized governance stack. We have shipped enough variations of this workflow to know what fails in production, what reviewer queues look like at scale, and what evaluation cadence actually catches drift. Reusable knowledge, not reusable code.
What to ask us before signing
- Ask for the labelled test set methodology — how many cases, what the coverage gaps are, who signs them off.
- Ask where the prompt library and retrieval index will live (your cloud or ours) and what happens to them at the end of Run.
- Ask how we calibrate confidence thresholds and how often they are revisited against the nonprofits reality.
- Ask for the audit log architecture — what is logged, how long it is retained, who can query it.
- Ask how a senior operator on your team becomes the first reviewer and what onboarding we ship to support them.
Recommended first project
Pick the executive reporting flow that has three properties: high enough weekly volume to produce a labelled test set quickly, structured enough to evaluate, and reversible if a decision is wrong. That is the wedge that ships fast, proves adoption, and earns the credibility to extend into the harder cases. The first 30 days are spent on the labelled test set, the integration to donor CRM, and the thin-slice workflow. The next 60 days are spent operating the thin slice on real nonprofits traffic, widening the automation envelope week by week. By day 90 you have an empirical track record, not a vendor's projection, and the next workflow can be scoped against that evidence.
Frequently asked questions
How do you automate executive reporting in nonprofits with AI?+
For nonprofits, the build is biased toward operational durability over demo-grade polish. We instrument every case end-to-end (intake → context → action → review), gate every prompt change behind an evaluation harness, and integrate against donor CRM + grant management. The workflow goes to production in 6-10 weeks and operates against reporting cycle time, decision clarity, follow-through, and executive alignment.
What does it cost to automate executive reporting for nonprofits teams?+
Phased pricing — you commit to one phase at a time. Discovery is $6k for 2-week sprint. Build, scoped from Discovery, runs $22k–$30k over 7-10 weeks. Run is opt-in at $3k–$5k / mo per optional, hourly bank also available. ~$34k–$60k typical year 1 (60% take the run option for ~6 months)
What is the best AI agent for executive reporting in nonprofits?+
The model is rarely the most consequential choice on executive reporting in nonprofits. What matters more: the retrieval shape against your approved sources, the confidence-threshold calibration against the labelled test set, the reviewer queue UX, and the audit log architecture. We benchmark frontier models (Claude, GPT-4-class, Gemini) against your data and select for the accuracy/cost/latency profile that fits your operational reality — not a generic leaderboard.
How long does it take to deploy AI executive reporting for nonprofits?+
Production traffic on executive reporting for nonprofits typically starts at week 6-8 of Build, after the labelled test set, the eval harness, the reviewer queue, and the audit log are all in place. The first quarter of Run is paired operation — your team takes the dashboard, we stay on the architecture decisions. By the end of the first Run quarter, your team is operating the workflow with the cadence we ship as part of Build.
What do we own, and what do you own?+
The ownership boundary is documented in the Build statement of work. Our side: workflow architecture, prompt library, retrieval shape, evaluation harness, reviewer-queue design, audit log architecture, weekly operating cadence. Your side: data access, source curation by your subject-matter experts, policy interpretation, exception approval, final commercial decisions. Every artefact is yours at the end of Run.
How fresh does the source corpus stay?+
Source freshness is a Run-phase deliverable, not a Build-phase promise. The retrieval index is refreshed on a documented cadence (weekly to monthly depending on source velocity), with stale-source detection in the eval harness. When a source goes stale enough to degrade quality, the eval harness catches it before users do.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
reporting cycle time, decision clarity, follow-through, and executive alignment measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with donor CRM and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on nonprofits engagements. Cited here so you can verify and dig deeper.
- Stanford Social Innovation Review
- Build for the Future: AI Maturity Survey — BCG
- Generative AI in the Enterprise — Deloitte AI Institute
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., Stanford
- Knowledge Worker Productivity in the AI Era — Microsoft Work Trend Index
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Nonprofits engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.