Financial Services · Risk & Compliance
Deploy a Governed AI Agent for Fraud and Risk Triage in Insurance
An engagement page for insurance carriers, brokers, claims leaders, underwriting teams, and distribution executives considering AI-native fraud and risk triage. We cover what we ship, how we operate it, what it costs, what controls travel with it, and how we report against the metrics your team already tracks.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native fraud and risk triage for insurance — Fixed-price phases that take fraud and risk triage from a Discovery baseline to a production thin slice on real insurance traffic, with the operating cadence handed over to your team by the end of Build. Expected delta on false positive rate: +210%.
Key facts
- Industry
- Insurance
- Use case
- Fraud and Risk Triage
- Intent cluster
- Risk & Compliance
- Primary KPI
- false positive rate, investigation time, loss avoided, and reviewer throughput
- Top benchmark
- Reviewer throughput per FTE: 1.0× → 3.1× (+210%)
- Systems integrated
- policy administration, claims platforms, broker portals
- Buyer
- insurance carriers, brokers, claims leaders, underwriting teams, and distribution executives
- Risk lens
- fair treatment, claims accuracy, underwriting bias, privacy, and auditability
- Engagement timeline
- Discovery 2 weeks → Build 9 weeks → Run continuous (integration-heavy)
- Team size
- 1 senior delivery + 1 part-time domain SME
- Discovery price
- $8k · 2-3 week sprint
- Build price
- $30k–$40k · 8-12 weeks
Primary outcome
prioritize risky activity before it becomes expensive
What we ship
risk triage assistant, case summaries, investigation workflows, and reviewer QA
KPIs we report on
false positive rate, investigation time, loss avoided, and reviewer throughput
Why Insurance teams hire us for this
The instinct in insurance is to either build everything internally or sign a multi-year retainer with a consulting firm. Neither option is well-matched to the speed of model and tooling changes in 2026. A scoped, phased AI-native engagement on fraud and risk triage lets you move fast on the build while keeping option value on what comes next.
Insurance compliance teams routinely report that reviewing AI-generated outputs is faster than reviewing human-generated outputs — as long as the AI system surfaces the supporting evidence at the same time. That is a design choice, not a model capability.
Industry context: Insurers operate under NAIC AI Model Bulletin + state-level constraints (Colorado, Connecticut led the AI legislation wave). Underwriting + claims AI must demonstrate non-discriminatory outcomes + explainability for adverse actions.
Benchmarks we hit
Reference benchmarks from production deployments of fraud and risk triage in insurance-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Reviewer throughput per FTE AI pre-assembles evidence; reviewer makes the policy decision in <2 min average | 1.0× | 3.1× | +210% |
Audit-log completeness Every inference call + reviewer action captured with version metadata | 62% | 100% | +38 pts |
Time-to-attestation Quarterly attestation packs assembled from audit log; reviewer signs off in hours | 21 days | 3 days | −86% |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
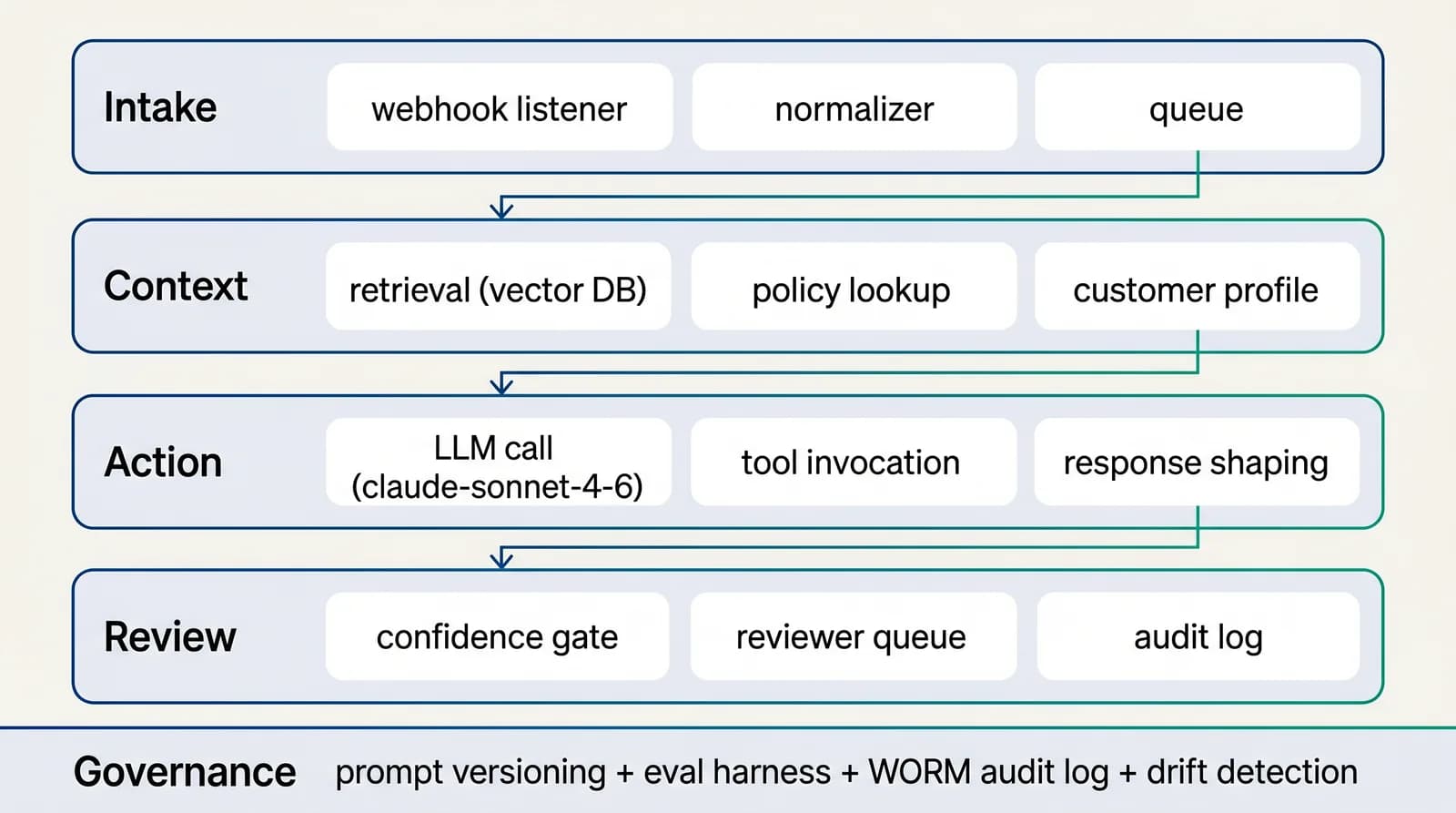
We treat the workflow as a system with five distinct layers: intake (classify and tag what comes in), context (retrieve approved sources), action (draft, route, decide), review (humans on low-confidence and high-impact cases), and learning (every reviewer action improves the next iteration). For fraud and risk triage in insurance, the layers are scoped during Discovery and built sequentially during Build.
What we build inside the workflow
The single most common mistake we see insurance teams make when Building fraud and risk triage is over-investing in prompt quality and under-investing in evaluation infrastructure. We invert that ratio: prompts are iterated weekly against a fixed labelled test set, and the labelled test set is treated as the most valuable artefact of the engagement. Without it, every change is a guess.
Reference architecture
4-layer AI-native workflow for risk & compliance
The architecture is designed for substitution: any single layer (model, retrieval store, reviewer UI, action client) can be swapped without rewriting the others. That is the property that lets fraud and risk triage survive 12+ months of provider and pricing change.See the full architecture diagram for Risk & Compliance →
AI-native vs traditional approach
The honest comparison for insurance carriers, brokers, claims leaders, underwriting teams, and distribution executives on fraud and risk triage: where AI-native delivery genuinely wins, where it is comparable, and where the traditional approach still makes sense.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Time-to-first-traffic | Multi-quarter program | 8-week thin-slice ship target |
| Commercial structure | Monthly retainer with FTE assumptions | Discovery, Build, Run priced independently |
| Control surface | Manual audit cycles | Versioned artefacts, signed audit log, named owners per control |
| Throughput-per-FTE | 1.0× (baseline) | +38 pts |
| Unit economics | Unchanged from baseline | 60-80% lower on routine cases |
| Termination clause | Multi-quarter notice; documentation gaps | Month-to-month Run; handover plan in Build SoW |
Manual claims triage costs $32-48 per claim touch; AI-native triage with grounded policy lookup brings it to $4-9, with reviewer queue on every coverage-edge case.
Engagement scope & pricing
Insurance engagements run as fixed-scope phases with named deliverables, not as hourly retainers. Each phase is independently committable.
Governed engagement
Phased delivery, separate billing. Commit only to what you can defend against the prior phase's output.
Phase 1 · Discovery
$8k
2-3 week sprint
Phase 2 · Build
$30k–$40k
8-12 weeks
Phase 3 · Run
$4k–$6k / mo
optional, quarterly attestations available
~$52k–$90k typical year 1 (~80% take the run option, regulated workflows need ongoing controls)
Controls, audit logs, reviewer queues, versioned prompts, and quarterly risk attestations.
The only thing you commit to today is the Discovery sprint. The Build SoW is produced inside Discovery and you decide whether to proceed. Run is optional.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Workflow mapping, integration scoping, baseline capture, risk register, labelled-test-set seed. The output is the Build SoW with a fixed price and named deliverables.
Phase 2 · Weeks 2–4
Design
Design phase is where the irreversible architectural choices are made: layer boundaries, substitution interfaces, governance posture, evaluation methodology. We invest disproportionately here because corrections in Build are 10× more expensive.
Phase 3 · Weeks 4–8
Build
Vertical-slice delivery against the labelled test set. Each slice ships to production, gated by eval criteria. By end of Build, the workflow is operating on real traffic with the calibration discipline established.
Phase 4 · Weeks 8+
Run
Run cadence is calibrated to your operational reality: weekly metric review, bi-weekly prompt refresh, monthly calibration audit, quarterly architecture review. The Run phase compounds value as the labelled test set grows.
Interactive ROI calculator
Estimate your AI-native ROI for fraud and risk triage
Reference inputs below are typical for insurance teams in the risk compliance cluster. Adjust them to match your situation.
Projected
Current monthly cost
$57,000
AI-native monthly cost
$20,070
Annual savings
$443,160
65% cost reduction · ~656 operator-hours freed / month
Governance and risk controls
Most "AI governance" frameworks insurance teams encounter are slide decks. Ours is a runtime: every inference call passes through guardrails (input filters, output validators, schema enforcement), every action is logged with the prompt and model version that produced it, every reviewer decision is captured. The framework documents what the runtime already enforces.
How we report ROI
Compounding is the under-rated ROI driver on fraud and risk triage. Week 1 of Run delivers the obvious gain — model handles the routine. By month 3, the prompt library, source corpus, and reviewer playbook are tuned to your specific insurance workflow. By month 6, the gap between your workflow and a generic AI agent is what makes the system hard to replace, internally or externally.
Selected portfolio
Real builds — fraud and risk triage in insurance and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with fraud and risk triage in insurance or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q3 2025
Radiology workflow application — case handling and reporting
Medical imaging operator · Europe
Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access.
- Web app + secure storage
- Structured reporting
- Audit-trail compliance
Q2 2026
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual
Mid-market property operator · GCC region
Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one.
- Next.js + tRPC
- Per-unit auth + audit trail
- Bilingual EN/AR (next-intl)
Q3 2025
Specialist automotive software-optimization site — multi-brand chiptuning
Vehicle optimization specialist · DACH region
Marketing site for an automotive software-optimization specialist serving multiple regions: brand-by-brand service architecture, technical service descriptions accessible to non-technical buyers, lead capture per service, regional-catchment SEO foundation.
- Next.js + responsive
- Multi-brand IA
- Regional SEO
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native fraud and risk triage engagements in insurance contexts.
Reviewer queue overflow
Volume spikes during incident windows; reviewers can't keep SLA, escalations stack
Confidence threshold raised dynamically during volume spikes; secondary reviewer pool on retainer
Compliance posture: what auditors and regulators expect
For insurance teams, regulatory exposure on fraud and risk triage typically clusters around four failure modes: customer harm from an incorrect automated decision, supervisory finding from inadequate documentation, internal audit gap from missing controls, and reputational damage from a poorly-explained system. Each failure mode has a distinct mitigation, and we wire all four into the Build phase rather than treating any of them as Run-phase patches.
Customer-harm mitigation begins with a confidence threshold calibrated against the labelled test set captured in Discovery. Anything below the threshold routes to a reviewer with the supporting evidence pre-assembled; the reviewer's decision feeds back into the calibration loop. Supervisory-finding mitigation is the audit log architecture — immutable, queryable, exportable — coupled with quarterly attestation packs that mirror the templates the supervisor uses in examinations of insurance firms. Audit-gap mitigation is the named-owner map: every control has a person, every person has a documented responsibility, and the map is on the same dashboard as the metrics. Reputational mitigation is the explainability layer — every decision the system communicates externally carries the supporting evidence so the recipient (and any downstream party) can interrogate it.
The combined posture is not "AI inside a compliance wrapper" — it is a workflow built for the regulated reality of insurance from week one. We have shipped this pattern across enough engagements to know which controls compress under scale, which controls drift over time, and which controls audit teams actually inspect. The Build statement of work names them all, the Run cadence keeps them current, and the dashboard makes them legible to anyone who needs to see them — operator, compliance, audit, regulator, board.
Third-party risk management for AI components in insurance is a growing concern that most workflows handle poorly. fraud and risk triage engagements typically depend on a model provider, a retrieval store, a vector database, sometimes a fine-tuning service. Each is a vendor in your risk register. We map them all during Build, document substitution paths for each, and demonstrate substitutability in the eval harness — so when one vendor changes pricing, terms, or availability, the workflow can move without a re-architecture.
Insurance regulatory expectations on AI have hardened over the last twenty-four months. Supervisors who would once accept "we use AI in this workflow" as a sufficient disclosure now ask for the model card, the validation evidence, the override path, and the customer-disclosure language. Vendors who built for the looser bar are scrambling. We built for the harder bar from the start, because the engagement model we sell insurance teams is one we can defend in front of any reasonable supervisor.
For fraud and risk triage, that defense rests on five artefacts the Build phase produces. The model card documents the deployed system: what it does, what it does not do, the training data lineage, the evaluation methodology, the known failure modes. The validation evidence is the labelled test set with its full provenance, the periodic eval reports, and the calibration curves. The override path is documented in the operator playbook and instrumented in the reviewer UI. The customer-disclosure language is drafted with your legal team during Build and tested with sample interactions before launch. The control map ties each control to a named owner and a measurable SLA.
The artefacts live in version control alongside the code, not in a shared drive. They are reviewed quarterly during Run and updated when the system changes. When a supervisor asks for them, the export is a single command. This is not theatre — it is the operating posture that lets your team say "yes, we use AI in this workflow, and here is the evidence we run it responsibly", with the evidence available in the time it takes to brew coffee.
How we ship the thin slice on this workflow
For insurance engagements on fraud and risk triage, the first 30 days are not about building features — they are about producing the labelled test set that will govern every subsequent decision. The test set is the most valuable artefact of the engagement, because it is what makes "did this change make the workflow better?" a measurable question instead of an opinion.
We spend week 1 on test-set capture. The operator team picks 200-400 representative cases spanning routine, exceptional, ambiguous, and adversarial. Each case has the expected outcome, the expected reasoning, and the source citations a reviewer would want to see. The test set is reviewed for coverage gaps, signed off by the engagement sponsor, and version-controlled alongside the prompts.
From week 2, every prompt change, retrieval-index update, and threshold calibration is gated by the eval harness running against this test set. Improvements that beat the incumbent across enough metric slices get promoted; changes that look impressive on one slice but regress on another are flagged for review. By the end of Build, the test set has grown to 600-1000 cases, the workflow has been through 15-25 eval cycles, and insurance leadership has empirical evidence that the system performs on their data, not on a vendor's demo.
This is the practice most insurance AI projects skip because it looks like overhead in the first three weeks. It is the practice that determines whether the workflow survives the third quarter of Run, which is why we treat it as the foundation of Build rather than an afterthought.
If you have ever shipped a non-trivial production system you know the first 30 days are make-or-break. For fraud and risk triage in insurance, the make-or-break decisions are: what does the labelled test set look like, what is in scope for the integration against policy administration, where does the automation boundary sit, and how is the reviewer queue UX going to feel to your operator team. We answer all four in the first two weeks.
Labelled test set: 200 cases minimum by end of week 2, signed off by the engagement sponsor, covering routine, exceptional, ambiguous, and adversarial. Integration scope: documented and bounded by end of week 1, with the data-access plan reviewed by your engineering team. Automation boundary: drawn deliberately in week 2 — full automation lane, drafted-with-review lane, reserved-to-human lane — with confidence thresholds calibrated against the test set. Reviewer UX: prototyped in week 2 with two of your senior operators in the loop, iterated through week 3.
From day 30, the Build sprint shifts to widening the envelope. The decisions made in the first month are the ones that shape the next 12 months of operating the workflow — which is why we resist the temptation to skip ahead to the model layer before the test set and the reviewer UX have been earned.
Pattern reference from a prior engagement
A comparable engagement worth knowing about for fraud and risk triage in insurance is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Radiology workflow application — case handling and reporting. Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access. (Medical imaging operator · Europe, Q3 2025.)
The architectural choices that worked there translate to insurance fraud and risk triage with two adjustments: the data-source mix shifts to match your operating systems (policy administration, claims platforms, and adjacent), and the reviewer SLAs adjust to your team's operating cadence. The four-layer pattern (intake, context, action, review), the evaluation discipline, and the audit posture are portable.
For US buyers
US compliance scaffolding for fraud and risk triage in insurance (NAIC AI Model Bulletin, GLBA, NIST AI RMF)
Insurance engagements touching US clients on fraud and risk triage ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for insurance is NAIC Model Bulletin on the Use of Artificial Intelligence Systems by Insurers (NAIC AI Model Bulletin) — addressed below alongside the adjacent frames we encounter.
NAIC AI Model Bulletin
NAIC Model Bulletin on the Use of Artificial Intelligence Systems by Insurers
Authority: National Association of Insurance Commissioners (model adopted by state insurance commissioners)
- Scope
- Insurer AI governance, model risk management, fairness testing, third-party AI vendor oversight, documentation, explainability.
- How we ship inside it
- Insurance engagements ship with the model governance documentation regulators expect: model inventory, validation evidence, drift monitoring, fairness testing on claim outcomes, vendor oversight clauses. The reviewer queue is designed for claims-handler supervisory review.
GLBA
Gramm-Leach-Bliley Act
Authority: FTC / federal banking regulators
- Scope
- Safeguarding non-public personal financial information (NPI), privacy notice, security programme requirements.
- How we ship inside it
- Engagements touching NPI follow GLBA Safeguards Rule: written information security programme, designated qualified individual, access controls, monitoring. NPI flows through encrypted channels only. Subprocessor agreements include GLBA flow-down clauses.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
Premium engagement page · hand-edited
The bespoke playbook for this combination
Claims triage and fraud detection with NAIC model governance, fairness testing, and claims-handler supervisory review.
Architecture, end-to-end
Claims triage AI for property and casualty (P&C), health, and specialty insurers. Routes claims by complexity, surfaces fraud signals with citations, drafts initial coverage decisions for handler review — under NAIC AI Model Bulletin governance.
Claim intake from your policy admin system (Guidewire ClaimCenter, Duck Creek, Origami) → classifier separating routine / complex / suspicious / catastrophic → adjudication assistant with policy-clause retrieval → fraud signal generation with linked evidence → claims-handler reviewer queue with explanation panel → audit log for state regulator review. Fairness testing on outcome distribution by protected attribute runs weekly; drift detection on classifier confidence runs daily.
Specific risks we engineer against
The four to six failure modes we have actually encountered on engagements that look like yours. Each has a documented mitigation in the Build SOW.
RiskDisparate impact on protected classes in claim outcomes
MitigationFairness testing on every model change, 4/5 rule baseline, escalation to model owner on any drift; documented per NAIC bulletin requirements.
RiskWrongful fraud flag damages customer relationship
MitigationFraud signals are surfaced to handler, not auto-applied. Handler decision is the only path to fraud designation. Customer-facing explanations are pre-drafted.
RiskState insurance commissioner challenges AI use
MitigationModel documentation, validation, governance map all aligned with NAIC AI Model Bulletin. Carrier-by-carrier filing support during Build.
RiskCatastrophic claim surge overwhelms reviewer capacity
MitigationSurge capacity plan in the operating runbook; auto-prioritisation rules calibrated to your claims SLA; escalation paths to senior adjusters.
Reference deltas on P&C claims engagements
| Metric | Before | After | Window |
|---|---|---|---|
| Claims triage cycle time | 4–8 hours | 15–30 minutes | 60 days |
| Fraud signal precision (handler-confirmed) | 12–18% | 35–50% | 90 days |
| Adjuster claims handled / day | 8–14 | 22–34 | 60 days |
| Customer NPS on claims experience | +18 | +34 | 120 days |
Reference values from P&C and specialty insurance engagements. Health insurance has different baseline windows.
Objections we hear most often
How do you handle state-by-state regulatory variance?+
Model behaviour is parameterised by state during Discovery. Filing support is part of Build for the first 3 states; subsequent states added during Run.
What if the model is biased?+
Fairness testing weekly with documented 4/5 rule baseline. Drift triggers escalation, not auto-deployment. Bias remediation is a documented Run activity.
Can we keep our existing fraud SIU workflow?+
Yes. The AI surfaces signals; your SIU still investigates. We integrate with your SIU case management.
Mini SOW
What the Build SOW looks like
Total fee
$30,000 Discovery + Build
Duration
12 weeks to thin-slice production
Week 1–2
Discovery: claim corpus sampled, NAIC governance framework aligned, fairness baseline captured.
Week 3–5
Classifier + retrieval index deployed; handler queue UI built.
Week 6–8
Shadow mode parallel to existing triage; 1000 claims processed in shadow.
Week 9–10
Cutover; 100% handler review; threshold calibration.
Week 11–12
Fairness validation report; carrier filing support delivered.
Procurement FAQ
Are you a third-party administrator?+
No. We are a technology delivery partner. Adjudication remains your TPA / claims department.
Do you cover model risk management?+
Yes. Full SR 11-7-aligned documentation (most insurers borrow this framework even where not strictly required).
Where do claims data sit?+
In your cloud region. We integrate via your policy admin system; we do not host claims data.
Real shipped systems
What our clients say
Below: attributions from active clients. Client identities are withheld in public form pending written approval; live references available to qualified procurement contacts on discovery call.
AI SaaS · DACH region
“They shipped the production version of our pricing brain in 6 weeks, including the billing layer and the onboarding flow. We had been bouncing between contractors for 4 months before.”
Founder, AI Pricing SaaS
Outcome: From 0 to live SaaS with paying customers in 6 weeks. Production billing live, AI onboarding flow shipped, 2 pricing tiers active.
Government-licensed legal services platform · GCC region
“A complete bilingual platform compliant with regulator requirements. Technical quality and delivery speed are outstanding.”
Founding team, regulated legal marketplace
Outcome: Ministry-of-Justice-licensed national legal marketplace, EN/AR bilingual, in 16 weeks. Directory + bookings + legal tools + emergency contacts.
Property management operator · GCC region
“We replaced spreadsheets and 4 disconnected tools with a single OA platform. 55 screens, 47 tables, a voting platform, and an internal portal — all on the same identity layer.”
CTO, multi-region property operator
Outcome: Centralised property operations across multiple owners associations. 14-week first release; 8-week follow-on for the staff portal; 6-week follow-on for e-voting.
Before / after
Concrete deltas from shipped engagements
Owners-association management workflows
Property management operator · GCC
Operator was scaling association count and could not maintain manual coordination. Replaced 4 fragmented tools with a single AI-augmented operational backbone.
Metric
Operational surface area
Before
Fragmented across spreadsheets + email + 4 SaaS tools
After (14 weeks Build phase)
Unified SaaS with 55 screens / 47 normalized tables / cross-app identity
Pricing strategy SaaS onboarding
AI pricing SaaS · DACH
Founder shipping AI-native pricing platform for early-stage SaaS. Discovery + Build delivered a working SaaS with subscription billing and an AI brain that learns from each customer.
Metric
Time-to-pricing for a new founder
Before
3–4 weeks of consultant time + spreadsheets
After (6 weeks total Build)
9-step structured AI workflow, completed in 30–45 minutes
Lawyer discovery and appointment booking
National legal marketplace · GCC
Regulated entity needed to launch the national reference platform for legal services. Delivered a Next.js 16 monorepo with bilingual content layer, PDF generation, and police directory.
Metric
Citizen access to certified legal services
Before
Fragmented across social media, no central directory, phone-only booking
After (16 weeks Discovery + Build)
Ministry-licensed bilingual EN/AR marketplace; multi-channel booking; legal tools; emergency hotline
Marketing site + booking funnel
Premium vehicle care specialist · DACH
Niche detailing workshop needed to project premium positioning matching their workmanship. AI-assisted copywriting + image art-direction compressed launch time.
Metric
Brand perception alignment
Before
Generic web presence — did not match workmanship quality
After (3 weeks concept-to-live (AI-augmented build))
Premium responsive site, German-market SEO foundation, appointment-oriented CTAs
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
The build-vs-buy decision in insurance usually comes down to four constraints: do you have AI engineering capacity, do you have ops capacity to govern it, do you have time-to-value pressure, and do you have a reference architecture to copy. We bring all four to an engagement. If you have two or fewer, working with us is faster and cheaper than building.
What to ask us before signing
- Ask for the labelled test set methodology — how many cases, what the coverage gaps are, who signs them off.
- Ask where the prompt library and retrieval index will live (your cloud or ours) and what happens to them at the end of Run.
- Ask how we calibrate confidence thresholds and how often they are revisited against the insurance reality.
- Ask for the audit log architecture — what is logged, how long it is retained, who can query it.
- Ask how a senior operator on your team becomes the first reviewer and what onboarding we ship to support them.
Recommended first project
Our recommendation for a first fraud and risk triage engagement in insurance is to pick the slice of the workflow that satisfies four criteria: there is a measurable baseline, the work is genuinely repetitive, the failure mode is reversible within a reasonable window, and a senior operator on your team can be the first reviewer. Those four criteria filter out the engagements that look impressive in a slide and fail in week three. The 90-day target is "thin slice in production with a defended baseline". By day 30, the system processes a small share of real traffic with full reviewer oversight. By day 60, the share has widened and the calibration is data-driven. By day 90, the operating cadence is your team's, the dashboard reflects empirical performance, and the case for the next workflow writes itself.
Frequently asked questions
How do you automate fraud and risk triage in insurance with AI?+
For insurance, the build is biased toward operational durability over demo-grade polish. We instrument every case end-to-end (intake → context → action → review), gate every prompt change behind an evaluation harness, and integrate against policy administration + claims platforms. The workflow goes to production in 6-10 weeks and operates against false positive rate, investigation time, loss avoided, and reviewer throughput.
What does it cost to automate fraud and risk triage for insurance teams?+
Phased pricing — you commit to one phase at a time. Discovery is $8k for 2-3 week sprint. Build, scoped from Discovery, runs $30k–$40k over 8-12 weeks. Run is opt-in at $4k–$6k / mo per optional, quarterly attestations available. ~$52k–$90k typical year 1 (~80% take the run option, regulated workflows need ongoing controls)
What is the best AI agent for fraud and risk triage in insurance?+
The model is rarely the most consequential choice on fraud and risk triage in insurance. What matters more: the retrieval shape against your approved sources, the confidence-threshold calibration against the labelled test set, the reviewer queue UX, and the audit log architecture. We benchmark frontier models (Claude, GPT-4-class, Gemini) against your data and select for the accuracy/cost/latency profile that fits your operational reality — not a generic leaderboard.
How long does it take to deploy AI fraud and risk triage for insurance?+
Production traffic on fraud and risk triage for insurance typically starts at week 6-8 of Build, after the labelled test set, the eval harness, the reviewer queue, and the audit log are all in place. The first quarter of Run is paired operation — your team takes the dashboard, we stay on the architecture decisions. By the end of the first Run quarter, your team is operating the workflow with the cadence we ship as part of Build.
What do we own, and what do you own?+
The ownership boundary is documented in the Build statement of work. Our side: workflow architecture, prompt library, retrieval shape, evaluation harness, reviewer-queue design, audit log architecture, weekly operating cadence. Your side: data access, source curation by your subject-matter experts, policy interpretation, exception approval, final commercial decisions. Every artefact is yours at the end of Run.
What's the auditor's experience of this AI workflow?+
The audit log is queryable on every dimension — input context, model version, retrieval bundle, output, reviewer disposition, downstream action. Pulling the evidence for a randomly-sampled case is a one-query operation. The control map ties each guardrail to a line of code that implements it and a named human owner.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
false positive rate, investigation time, loss avoided, and reviewer throughput measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with policy administration and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on insurance engagements. Cited here so you can verify and dig deeper.
- NAIC AI Resources
- Responsible Scaling Policy — Anthropic
- AI Index Report — Stanford HAI
- AI/ML Software as a Medical Device Action Plan — U.S. FDA
- Generative AI: Charting a Path to Responsibility — OECD.AI
- NAIC Model Bulletin on AI — National Association of Insurance Commissioners
- EIOPA Thematic Review on AI in Insurance — European Insurance and Occupational Pensions Authority
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
Concepts on this page:
AI governance·NIST AI RMF·Audit log·Grounding·Guardrails·Model cardFull glossary →High-intent reads
Start the engagement
Start a Insurance engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.