Travel and Hospitality · Risk & Compliance
Cut Contract Review Time 70% in Hotels (Audit-Ready)
For hotel owners, revenue managers, guest experience teams, and multi-property operators ready to move contract review from manual operation to instrumented AI-native delivery. Below: the workflow we ship, the operating model that keeps it improving, the governance posture, and the commercial envelope.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native contract review for hotels — A phased engagement that ships a production contract review workflow on top of PMS and CRS, moves the operating metric against a Discovery-captured baseline, and is operated under explicit governance from day one. Expected delta on review cycle time: +38 pts.
Key facts
- Industry
- Hotels
- Use case
- Contract Review
- Intent cluster
- Risk & Compliance
- Primary KPI
- review cycle time, fallback usage, negotiation rounds, and contract leakage
- Top benchmark
- Audit-log completeness: 62% → 100% (+38 pts)
- Systems integrated
- PMS, CRS, channel managers
- Buyer
- hotel owners, revenue managers, guest experience teams, and multi-property operators
- Risk lens
- brand reputation, guest privacy, service consistency, and margin leakage
- Engagement timeline
- Discovery 2 weeks → Build 6 weeks → Run continuous
- Team size
- 1 senior delivery + founder oversight
- Discovery price
- $8k · 2-3 week sprint
- Build price
- $30k–$40k · 8-12 weeks
Primary outcome
speed up legal and commercial review while protecting standards
What we ship
clause playbook, contract review assistant, redline workflow, and fallback library
KPIs we report on
review cycle time, fallback usage, negotiation rounds, and contract leakage
Why Hotels teams hire us for this
The reason contract review is a high-ROI wedge for hotels is not the AI capability — it is the gap between what the workflow currently is (siloed, inconsistent, hard to measure) and what it can become (instrumented, reviewable, improvable). AI is the lever; operating discipline is the fulcrum. We ship both.
BIS and OECD guidance on AI in regulated sectors (including hotels) converges on a common requirement: explainable decisions, traceable inputs, versioned models. Our control stack is built against that requirement, not retrofitted.
Industry context: Hotels operate with thin per-stay margins (12-18% GOP typical), high seasonality (RevPAR swings 40%+ peak-to-trough), and labor as the largest cost line (35-45% of revenue). Guest-data privacy under GDPR + CCPA + state-level constraints adds review burden.
Benchmarks we hit
Reference benchmarks from production deployments of contract review in hotels-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Audit-log completeness Every inference call + reviewer action captured with version metadata | 62% | 100% | +38 pts |
Time-to-attestation Quarterly attestation packs assembled from audit log; reviewer signs off in hours | 21 days | 3 days | −86% |
Loss avoided / quarter (vs no AI) Conservative estimate; actuals depend on fraud volume + ticket size | $0 (no AI lift) | $280k median | Net positive |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
When hotels leaders ask how we run contract review differently from a typical consulting engagement, the honest answer is: we never stop running it. The Build phase produces the workflow, but the operating model — weekly reviews, edge-case folding, calibration drift detection — is what compounds value. Without it, AI accuracy degrades silently within months.
What we build inside the workflow
The Build deliverable for contract review in hotels is not a model — it is an operating system around a model. The model is the cheap part (Claude or GPT-4-class, swappable). The operating system — eval harness, reviewer queue, audit log, governance map, runbook — is the expensive part, and the part that determines whether the workflow survives the second quarter of production.
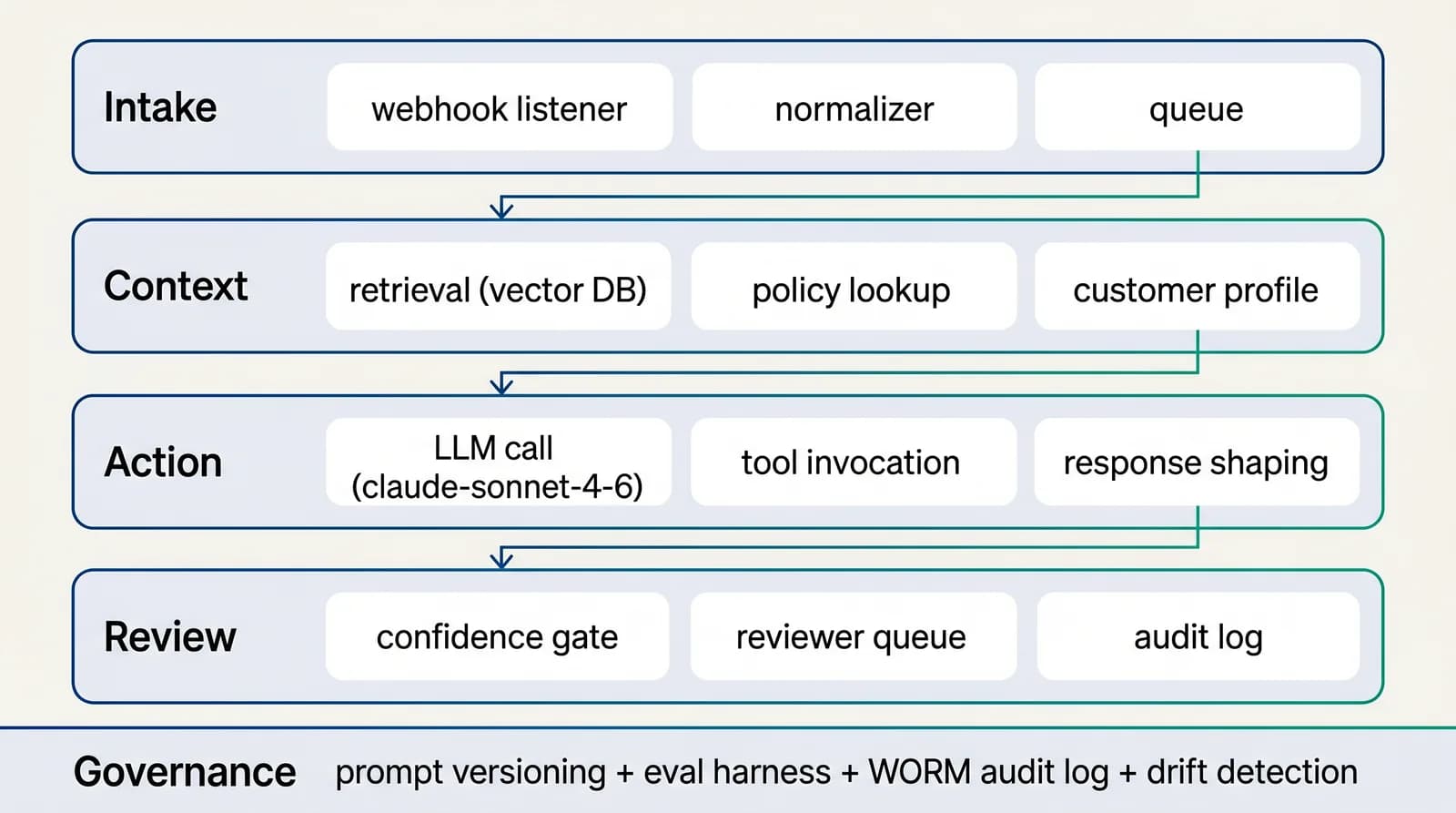
Reference architecture
4-layer AI-native workflow for risk & compliance
The reference architecture treats prompts and retrieval as code: version-controlled, evaluated on every change, deployed through CI. That posture is what makes contract review legible to engineering audit twelve months in.See the full architecture diagram for Risk & Compliance →
AI-native vs traditional approach
Side-by-side comparison of an AI-native engagement against the alternatives most hotels teams evaluate for contract review: time to production, pricing model, governance posture, operator throughput, unit cost, exit path.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Time to production | Two quarters minimum | Production traffic within 6-10 weeks |
| Pricing model | FTE hourly retainer or fixed staffing | Three independent commercial envelopes |
| Audit / governance | Document-driven, periodic snapshot | Runtime guardrails + audit log + governance map + quarterly attestation |
| Operator throughput lift | 1.0× (baseline) | −86% |
| Cost per unit | Linear with operator headcount | Typically 60-80% lower |
| End-of-engagement | Multi-quarter notice + knowledge loss | Month-to-month Run, full handover plan in Build SoW |
Traditional revenue management vendors charge 1-2% of total revenue; AI-native RM brings the cost to flat $4-8k/mo with cluster-aware pricing for resorts vs urban properties.
Engagement scope & pricing
Contract Review delivery is structured as Discovery → Build → opt-in Run, each priced and scoped independently. No multi-quarter retainer commitments.
Governed engagement
Three commercial envelopes, three deliverables. The next phase is scoped against the evidence the prior phase produced.
Phase 1 · Discovery
$8k
2-3 week sprint
Phase 2 · Build
$30k–$40k
8-12 weeks
Phase 3 · Run
$4k–$6k / mo
optional, quarterly attestations available
~$52k–$90k typical year 1 (~80% take the run option, regulated workflows need ongoing controls)
Controls, audit logs, reviewer queues, versioned prompts, and quarterly risk attestations.
Discovery contains its own value (the workflow map, the baseline, the SoW). You can stop after Discovery and still own the artefacts. If you proceed, Build is fixed-scope and fixed-price.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
We sit with the operator team running the workflow today, watch a working day end-to-end, and produce the baseline that Build will be measured against. Two-week sprint, fixed price.
Phase 2 · Weeks 2–4
Design
Design phase is where the irreversible architectural choices are made: layer boundaries, substitution interfaces, governance posture, evaluation methodology. We invest disproportionately here because corrections in Build are 10× more expensive.
Phase 3 · Weeks 4–8
Build
Build is paced by the evaluation harness: every prompt change must beat the incumbent on the labelled test set across enough metric slices to be promoted. The harness is what makes Build defensible.
Phase 4 · Weeks 8+
Run
Optional Run phase, month-to-month, no lock-in. Weekly performance review against the Discovery baseline. Quarterly architecture retrospective. The cadence is documented; your team can absorb it any time.
Interactive ROI calculator
Estimate your AI-native ROI for contract review
Reference inputs below are typical for hotels teams in the risk compliance cluster. Adjust them to match your situation.
Projected
Current monthly cost
$57,000
AI-native monthly cost
$20,070
Annual savings
$443,160
65% cost reduction · ~656 operator-hours freed / month
Governance and risk controls
For hotels teams operating under brand reputation, guest privacy, service consistency, and margin leakage, the governance stack we ship is opinionated: source allow-lists curated by your subject-matter expert, prompt versioning gated by your evaluation harness, reviewer queues staffed by your team, audit logs retained per your data policy. We bring the architecture; you bring the policy. The combination is what auditors recognize as defensible.
How we report ROI
The ROI metric that matters most for hotels leadership on contract review is not labor savings — it is opportunity capture. Faster review cycle time means more cases handled in the same window, more revenue, more compliance coverage, more customer trust. We measure both: the costs that drop and the throughput that scales.
Selected portfolio
Real builds — contract review in hotels and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with contract review in hotels or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q3 2025
Radiology workflow application — case handling and reporting
Medical imaging operator · Europe
Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access.
- Web app + secure storage
- Structured reporting
- Audit-trail compliance
Q2 2026
Authenticated remote voting platform — AGM resolutions, audit trail, EN/AR bilingual
Mid-market property operator · GCC region
Purpose-built e-voting system: per-unit cryptographic authentication, AGM resolution console for admins, real-time tally, full per-vote audit log. Federated identity with the OA management platform so owners use one login. Bilingual EN/AR from day one.
- Next.js + tRPC
- Per-unit auth + audit trail
- Bilingual EN/AR (next-intl)
Q4 2025 → Q1 2026
Owners-association management SaaS — 55+ screens, 47 normalized tables
Mid-market property operator · GCC region
Full operational backbone for a property operator running multiple owners associations: properties, units, owners, accounting, service charges, budgets, maintenance, violations, and a resident-facing community portal — replacing a patchwork of spreadsheets and disconnected accounting tools.
- Next.js + tRPC
- PostgreSQL · Drizzle ORM
- JWT federated identity
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native contract review engagements in hotels contexts.
Regulator surprise at first attestation
Audit trail is incomplete; reviewer left a 3-week gap in week 4
Audit log designed as primary artifact (not log-as-afterthought); weekly attestation rehearsal
Designing for the consumer scale of this category
What separates a consumer-grade contract review workflow from a B2B one in hotels is the asymmetry between routine and exceptional cases. The routine drives the unit economics; the exceptional drives the public perception. AI-native delivery lets you optimize both at once instead of trading them off.
On routine volume, the AI handles the work with consistent quality and sub-second turnaround. The throughput-per-operator improvement is what justifies the engagement in the CFO's spreadsheet. Concretely, for hotels, we typically see a 3-5x throughput lift on routine cases inside the first quarter of Run, with quality variance dropping by half. The operator team is not eliminated — it is redirected at the exceptional cases where its judgment compounds.
On exceptional cases, the architecture inverts: the AI's job is to surface the context, the policy clauses, the customer history, the prior similar cases — not to generate a confident answer. The operator's job is to apply judgment with the supporting evidence pre-assembled. The post-resolution review feeds the labelled test set so the next similar case is handled with deeper context. For hotels, this is what turns a one-off support frustration into a system improvement; for the operator, it is what turns reactive triage into deliberate craft.
The combined effect, visible in the dashboards by month three, is a workflow where routine work scales without degrading quality and exceptional work compounds operator knowledge instead of dissipating it. That dual outcome is the reason consumer-facing hotels teams adopt AI-native delivery on contract review — not because the AI is impressive, but because the asymmetry between the two case types finally has a workflow shaped to it.
Week-by-week shape of the Build phase
Most hotels AI projects fail in the first month for the same reason: too much time in scoping, too little in shipping. Our Build phase inverts that ratio deliberately. Week 1 has running code; week 4 has reviewable thin-slice production traffic; week 6 has a defensible accuracy baseline against the labelled test set.
The shape of the first week is opinionated. By end of day Wednesday, the retrieval index is loaded with the first batch of approved sources. By end of day Friday, the intake classifier is hitting the labelled test set with an initial accuracy number. The number is intentionally not impressive — it is a baseline against which weeks 2 and 3 measure progress. Most teams underestimate how motivating that early concrete number is for both the operator team (it stops feeling abstract) and the engineering team (the eval feedback loop is closing).
From week 2 onward the cadence is metric-driven. Every Friday produces a delta report against the labelled test set: which slices improved, which regressed, what the next iteration targets. The operator team participates in the Friday review; their judgment on edge cases becomes the next iteration's prompt or retrieval tweak. By week 6, the system has been through 12-15 evaluation cycles, each with hotels-specific calibration, each tied to a documented change. The workflow that hits production at the end of Build is the workflow that has survived a month of empirical correction, not the workflow that looked good in the architecture diagram.
Our Build cadence on contract review for hotels is bias-corrected against the two failure modes we have seen kill hotels AI projects most often: scoping that drifts week-by-week, and a labelled test set that arrives in week 6 instead of week 1.
We fix the scoping by signing the Build statement of work before any code is written — the deliverables are named, the integration footprint is bounded, the milestones have dates. We fix the labelled test set timing by treating it as the week-1 deliverable. Week 1 is not "scoping week" — it is "labelled-test-set week", because every subsequent engineering decision is measured against that test set.
Week 2: retrieval index live with first batch of approved sources. Week 3: intake classifier scoring against the test set, first calibration report. Week 4: action layer drafting with reviewer approval; first end-to-end case flow. Week 5-6: thin slice in production on 5-15% of routine hotels traffic, first weekly review with the operator team. Weeks 7-10: production envelope widens case-class by case-class, calibration loop tunes against the empirical evidence, exceptional cases route to enriched escalation. By day 60-70, the workflow is operating at its target envelope.
A working example of this pattern
The recent build in our portfolio that maps cleanest to contract review in hotels is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
Radiology workflow application — case handling and reporting. Application supporting radiology workflow: case intake, structured reporting, document handling, and quality-assurance loop. Designed for regulated medical-imaging context with audit trail and role-based access. (Medical imaging operator · Europe, Q3 2025.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to hotels (PMS and the adjacent systems) and the prompt strategy tuned to the contract review vernacular in your category.
For US buyers
US compliance scaffolding for contract review in hotels (CCPA / CPRA, NIST AI RMF)
Hotels engagements touching US clients on contract review ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for hotels is California Consumer Privacy Act / California Privacy Rights Act (CCPA / CPRA) — addressed below alongside the adjacent frames we encounter.
CCPA / CPRA
California Consumer Privacy Act / California Privacy Rights Act
Authority: California Privacy Protection Agency (CPPA)
- Scope
- California resident data rights (access, deletion, opt-out of sale/sharing), sensitive personal information, automated decision-making opt-out (proposed regs).
- How we ship inside it
- California-touching engagements ship with consumer-rights workflows: access request handling, deletion within 45 days, opt-out signals (GPC) honored at the retrieval layer. Automated-decision-making disclosures align with proposed CPPA regulations.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
Hotels teams that build successfully in-house tend to have an existing ML platform, a labelled data culture, and a product manager dedicated to the workflow. If any of those is missing, the project tends to stall at proof-of-concept. We replace those three dependencies with a scoped engagement and a senior delivery team.
What to ask us before signing
- Ask for a workflow map that shows intake, retrieval, generation, review, escalation, system updates, and measurement.
- Ask for an evaluation plan using real examples from hotels, not only generic test prompts.
- Ask how we will move review cycle time, fallback usage, negotiation rounds, and contract leakage within the first 30 to 60 days.
- Ask which parts of the process remain human-owned and why.
- Ask for our exit plan: what stays with you if the engagement ends.
Recommended first project
The first project we recommend for hotels on contract review is rarely the one leadership names in the initial conversation. The named project is usually the most politically visible — which is also the riskiest place to ship a first AI-native workflow. We typically recommend the adjacent subflow with the cleanest baseline, the smallest blast radius, and the most repetitive operator work. That first project produces three artefacts that the visible project needs: a labelled test set the operator team has signed off on, a reference architecture against PMS, and a credibility track record with the internal stakeholders who will be asked to support the second engagement. By the time we propose the second workflow — the visible one — the organisational gravity is on our side.
Frequently asked questions
How does AI contract review work for hotels?+
We build a clause playbook from your standard terms, then the AI reads incoming agreements — group-sales contracts, OTA agreements, banquet and vendor contracts — and flags deviations: attrition clauses, cancellation terms, force-majeure language, rate-parity commitments. It drafts the comparison and suggested redlines; your commercial lead or counsel makes the legal judgment and approves deviations. Review cycle time is the KPI we report on, measured against how long the same contract types took before the build.
How do you automate contract review in hotels with AI?+
Three phases. Discovery (2 weeks) produces the labelled test set, the system map, and the Build statement of work. Build (6-10 weeks) ships a thin-slice production deployment on top of PMS and adjacent systems, with versioned prompts and a reviewer queue. Run (optional, month-to-month) operates the workflow weekly against review cycle time, fallback usage, negotiation rounds, and contract leakage.
What does it cost to automate contract review for hotels teams?+
Three phases, billed separately. Discovery sprint: $8k (2-3 week sprint). Build engagement: $30k–$40k (8-12 weeks). Run retainer: $4k–$6k / mo (optional, quarterly attestations available). ~$52k–$90k typical year 1 (~80% take the run option, regulated workflows need ongoing controls). Controls, audit logs, reviewer queues, versioned prompts, and quarterly risk attestations.
What is the best AI agent for contract review in hotels?+
There is no single "best" off-the-shelf agent for contract review in hotels — the right architecture depends on your PMS setup, your data, and your risk profile. We typically combine a frontier LLM (Claude, GPT-4-class, or Gemini) with a retrieval layer over your approved sources, tool-use for PMS and CRS integrations, and a reviewer queue. We benchmark candidate models against a labelled test set during Discovery and pick the one with the best accuracy/cost ratio for your workflow.
How long does it take to deploy AI contract review for hotels?+
End-to-end lead time from kickoff to thin-slice production: 6-10 weeks. End-to-end to full operating envelope: 10-14 weeks. review cycle time, fallback usage, negotiation rounds, and contract leakage is instrumented from day one of Build; the dashboard goes live by week 4-5; production traffic starts by week 6-8. By 90 days, leadership has a 30-60 day record of operating performance against the Discovery baseline.
What do we own, and what do you own?+
We own the workflow design, the prompts, the retrieval architecture, the evaluation harness, and weekly improvement. Your hotel owners, revenue managers, guest experience teams, and multi-property operators team owns data access, policy, exception approval, and final commercial decisions. At the end of the engagement, every prompt, eval, and config is handed over — no lock-in.
How do you keep contract review defensible to supervisors and internal audit?+
Three properties wired into the architecture: explainability (every decision ships with supporting evidence), replayability (every inference call is reconstructible from the audit log), segregation of duties (lanes for full automation, drafted-with-review, reserved-to-human are documented and instrumented). Together they answer the three questions internal audit and supervisors ask about contract review in hotels.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
review cycle time, fallback usage, negotiation rounds, and contract leakage measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with PMS and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on hotels engagements. Cited here so you can verify and dig deeper.
- UN Tourism Digital Transformation
- The State of AI — McKinsey & Company
- Build for the Future: AI Maturity Survey — BCG
- Generative AI: Charting a Path to Responsibility — OECD.AI
- Model Risk Management Handbook — Federal Reserve (SR 11-7)
- AHLA State of the Industry — American Hotel & Lodging Association
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
Concepts on this page:
AI governance·NIST AI RMF·Audit log·Grounding·Guardrails·Model cardFull glossary →High-intent reads
Start the engagement
Start a Hotels engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.