Real Assets · Knowledge & Insight
AI-Native Data Analytics for Construction Leaders
For general contractors, developers, project managers, estimators, and field operations teams ready to move data analytics from manual operation to instrumented AI-native delivery. Below: the workflow we ship, the operating model that keeps it improving, the governance posture, and the commercial envelope.
Projects from $15k · Refundable 7 days · Kickoff within 5 days
Early access: we work with a small first cohort. Engagements are scoped, priced, and shipped end-to-end by our team — not referred to third parties.
In one sentence
AI-native data analytics for construction — An AI-native data analytics workflow built against your existing BIM stack, calibrated against a labelled test set of real construction cases, and operated against the KPIs your CFO recognises. Expected delta on time to insight: −83%.
Key facts
- Industry
- Construction
- Use case
- Data Analytics
- Intent cluster
- Knowledge & Insight
- Primary KPI
- time to insight, dashboard adoption, decision cycle time, and anomaly response
- Top benchmark
- Decision cycle time: 9 days → 1.5 days (−83%)
- Systems integrated
- BIM, ERP, project management
- Buyer
- general contractors, developers, project managers, estimators, and field operations teams
- Risk lens
- site safety, contract terms, schedule slippage, cost overruns, and document version control
- Engagement timeline
- Discovery 2 weeks → Build 9 weeks → Run continuous (integration-heavy)
- Team size
- 1 senior delivery + 1 part-time domain SME
- Discovery price
- $6k · 2-week sprint
- Build price
- $22k–$30k · 7-10 weeks
Primary outcome
turn raw data into faster operational decisions
What we ship
analytics copilot, metric dictionary, insight workflows, and executive narratives
KPIs we report on
time to insight, dashboard adoption, decision cycle time, and anomaly response
Why Construction teams hire us for this
Construction runs on BIM, ERP, project management and adjacent systems. Most automation projects in this space stop at integration — they move data, but they do not change how decisions are made. AI-native data analytics starts from the decision itself: which step needs evidence, which step needs judgment, which step can run unattended once governance is in place.
Microsoft's Work Trend Index data shows that knowledge workers in construction spend up to 30% of the week searching for or recreating information that already exists internally. Source-grounded retrieval is the highest-leverage AI use case in this segment.
Industry context: Mid-market and enterprise operators face the same fundamental tradeoff: AI must compress operational cycle time while remaining auditable and integrable with existing systems of record.
Benchmarks we hit
Reference benchmarks from production deployments of data analytics in construction-comparable contexts. Sources noted per row. Your actuals are measured against the baseline captured in Discovery.
| Metric | Industry baseline | AI-native typical | Delta |
|---|---|---|---|
Decision cycle time Insight assembly compressed from manual deck-building to instrumented dashboard | 9 days | 1.5 days | −83% |
Cost per executive briefing Analyst time reallocated from assembly to validation and narrative | $1 800 | $340 | −81% |
Source citation completeness Every claim grounded in approved source with replayable retrieval bundle | 38% | 100% | +62 pts |
Benchmarks are reference values from comparable engagements and authoritative sector benchmarks. Your engagement's baseline is captured during Discovery and actuals are reported weekly during Run against that baseline.
How we operate the workflow
When construction leaders ask how we run data analytics differently from a typical consulting engagement, the honest answer is: we never stop running it. The Build phase produces the workflow, but the operating model — weekly reviews, edge-case folding, calibration drift detection — is what compounds value. Without it, AI accuracy degrades silently within months.
What we build inside the workflow
Where most AI projects in construction stop is at the prototype that works on cherry-picked inputs. Our Build phase deliberately stresses data analytics on edge cases, adversarial inputs, malformed records, and the long tail of exceptions that real production traffic produces. The thin slice shipping to production has already passed those tests.
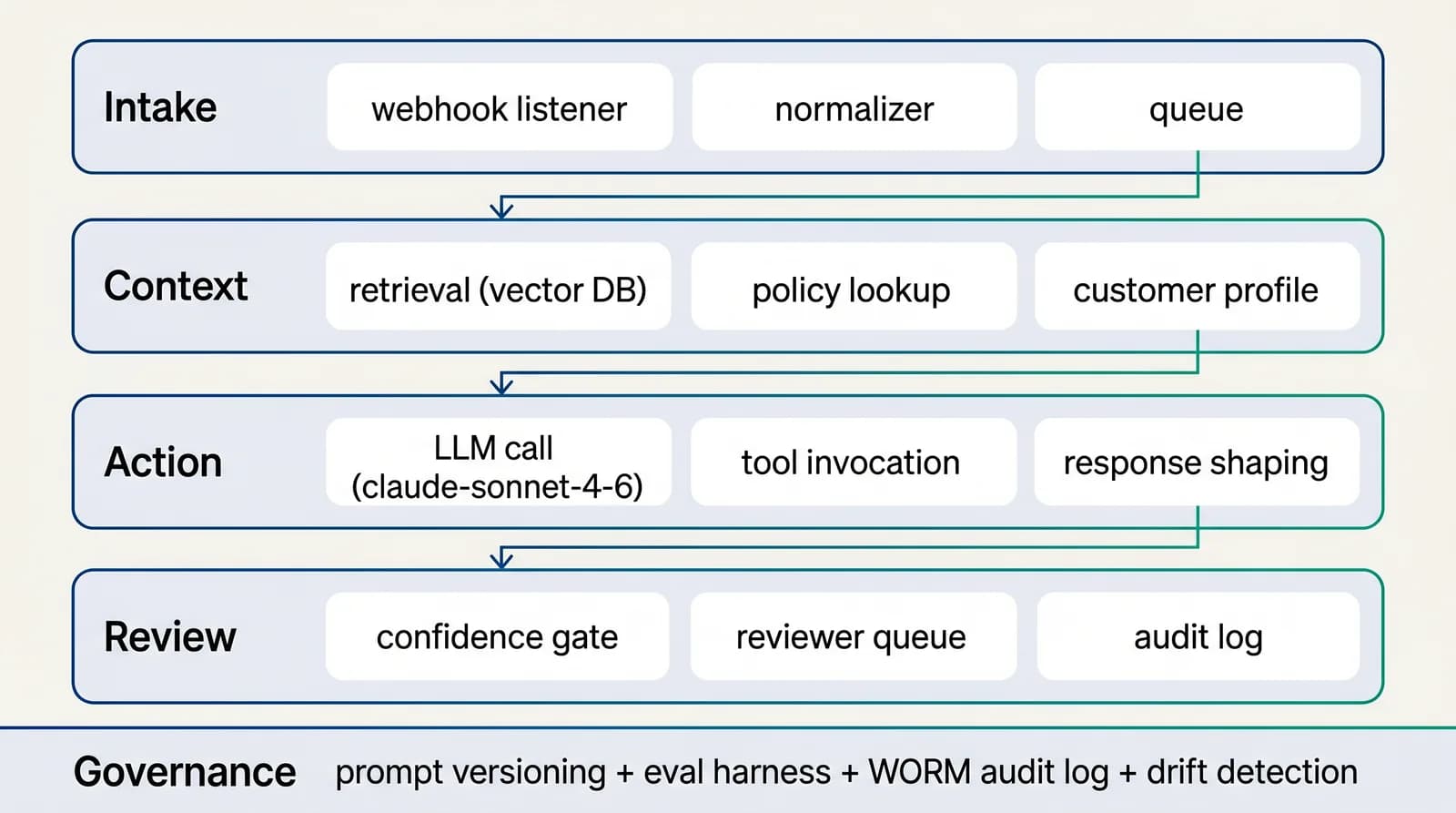
Reference architecture
4-layer AI-native workflow for knowledge & insight
The architecture is designed for substitution: any single layer (model, retrieval store, reviewer UI, action client) can be swapped without rewriting the others. That is the property that lets data analytics survive 12+ months of provider and pricing change.See the full architecture diagram for Knowledge & Insight →
AI-native vs traditional approach
Side-by-side comparison of an AI-native engagement against the alternatives most construction teams evaluate for data analytics: time to production, pricing model, governance posture, operator throughput, unit cost, exit path.
| Dimension | Traditional (in-house build or BPO) | AI-native engagement (us) |
|---|---|---|
| Lead time to live deployment | 6-12 months | 6-10 weeks (thin slice) |
| Engagement billing | Time-and-materials or annual contract | Phased fixed-price (Discovery → Build → opt Run) |
| Audit posture | Manual logs, periodic review | Versioned prompts, audit logs, reviewer queues, attestations |
| Per-operator capacity | 1.0× (baseline) | −81% |
| Per-case cost | Industry baseline | Sub-dollar marginal cost on routine envelope |
| Exit path | Knowledge transfer takes 6+ months | Documented exit at every phase; artefacts in your repo |
Traditional process automation projects cost $80-200k+ with 6-12 month payback; AI-native engagements deliver thin-slice production in 6-8 weeks with measurable baseline-vs-actuals reporting.
Engagement scope & pricing
Data Analytics delivery is structured as Discovery → Build → opt-in Run, each priced and scoped independently. No multi-quarter retainer commitments.
Insight engagement
Three commercial envelopes, three deliverables. The next phase is scoped against the evidence the prior phase produced.
Phase 1 · Discovery
$6k
2-week sprint
Phase 2 · Build
$22k–$30k
7-10 weeks
Phase 3 · Run
$3k–$5k / mo
optional, hourly bank also available
~$34k–$60k typical year 1 (60% take the run option for ~6 months)
Source curation, retrieval architecture, evaluation harness, and decision dashboards.
The only thing you commit to today is the Discovery sprint. The Build SoW is produced inside Discovery and you decide whether to proceed. Run is optional.
The 4-phase delivery model
Phase 1 · Weeks 1–2
Discovery
Discovery is short, intense, and decision-producing. By end of week 2, you have the workflow map, the baseline, the SoW, and the risk register. No code yet — the next phase is calibrated against this evidence.
Phase 2 · Weeks 2–4
Design
Design phase is where the irreversible architectural choices are made: layer boundaries, substitution interfaces, governance posture, evaluation methodology. We invest disproportionately here because corrections in Build are 10× more expensive.
Phase 3 · Weeks 4–8
Build
Vertical-slice delivery against the labelled test set. Each slice ships to production, gated by eval criteria. By end of Build, the workflow is operating on real traffic with the calibration discipline established.
Phase 4 · Weeks 8+
Run
Run cadence is calibrated to your operational reality: weekly metric review, bi-weekly prompt refresh, monthly calibration audit, quarterly architecture review. The Run phase compounds value as the labelled test set grows.
Interactive ROI calculator
Estimate your AI-native ROI for data analytics
Reference inputs below are typical for construction teams in the knowledge insight cluster. Adjust them to match your situation.
Projected
Current monthly cost
$26,400
AI-native monthly cost
$6,684
Annual savings
$236,592
75% cost reduction · ~1,672 operator-hours freed / month
Governance and risk controls
We map every construction engagement against the NIST AI RMF functions (Govern, Map, Measure, Manage) during Discovery. The risk register we produce covers site safety, contract terms, schedule slippage, cost overruns, and document version control, and it drives the design choices in Build: which decisions get full automation, which get assisted review, which require explicit human approval. The map is a living artefact reviewed quarterly during Run.
How we report ROI
We refuse to project ROI before Discovery. The honest answer for most construction engagements is: we will compress the cycle for turn raw data into faster operational decisions by 30-70%, lift consistency on time to insight, dashboard adoption, decision cycle time, and anomaly response, and reduce reviewer load on the routine cases — but the magnitude depends on the baseline we measure together. The Discovery report contains the projection.
Selected portfolio
Real builds — data analytics in construction and adjacent sectors
Below are engagements drawn from our active portfolio where the workflow rhymed with data analytics in construction or in adjacent contexts. Scope and stack are accurate; client identities are withheld under engagement NDAs.
Q1 2026
AI-powered interior design platform — generative room concepts for the MEA market
AI interior design SaaS · MEA region
Vertical AI SaaS for interior design in the Middle East: image-conditioned generation tuned for local taste profiles, room-by-room concept workflow, project export for designers and clients. Built with a market-specific dataset and an evaluation loop on regional aesthetic baselines.
- Next.js + image generation pipeline
- Regional taste-profile tuning
- Designer + client export flows
Q1 2026
AI pricing system for startup founders — 9-step foundation + personalised AI brain
Founder-led pricing-strategy AI SaaS · DACH
First AI-powered pricing platform for startup founders. Structured 9-step pricing-foundation flow (product, customers, competition, costs, boundaries, model, strategy), personalised AI brain that learns from each business over time, two subscription tiers with money-back guarantee. Built end-to-end including billing, AI orchestration, and onboarding.
- Next.js + TypeScript
- Multi-LLM orchestration
- Subscription billing
Q4 2025 → Q1 2026
Owners-association management SaaS — 55+ screens, 47 normalized tables
Mid-market property operator · GCC region
Full operational backbone for a property operator running multiple owners associations: properties, units, owners, accounting, service charges, budgets, maintenance, violations, and a resident-facing community portal — replacing a patchwork of spreadsheets and disconnected accounting tools.
- Next.js + tRPC
- PostgreSQL · Drizzle ORM
- JWT federated identity
Client identities withheld under engagement NDAs. Sector, geography, and scope are accurate. Full case studies on request.
Common pitfall & mitigation
The failure mode we see most often on AI-native data analytics engagements in construction contexts.
Stale corpus, current answers
Sources indexed in February, AI confidently cites them in October as 'current'
Freshness scoring on every retrieval; flag stale citations + auto-trigger SME refresh workflow
Designing for an operation that is partly in the building
The signal that matters most in construction operations is the gap between the schedule and the actual. The dashboard tells you what was planned; the field tells you what happened; the variance is where the operating leverage lives. AI-native delivery is at its best when the workflow surfaces that variance early, attributes it to the right cause class, and routes corrective action to the right owner — before the next scheduling cycle commits the same assumption.
Engineering for graceful degradation in construction data analytics workflows is not a nice-to-have — it is the property that keeps the operation running when the model provider is slow, the integration partner is down, or the field connectivity drops. We design the workflow with explicit fallback paths at every layer: routine decisions can be executed from cached policy, exceptional decisions can queue with prioritized re-route, escalations always have a manual lane. The workflow degrades gracefully because it was built to.
The instinct in construction data analytics engagements is to centralize — pull all the field data into the central system, run AI on the consolidated view, push decisions back out. That instinct is half right. The data does need to be consolidated for analysis; the decisions often do not need to be centralized to be made well.
Our architecture for construction workflows is hybrid by default. The central layer holds the consolidated view, the model registry, the retrieval index, the analytics. The field layer holds the lightweight decision interface, the offline-capable capture surface, and the local cache for routine decisions. The boundary is drawn case by case: routine data analytics decisions execute at the edge with central audit; exceptional decisions route to the central reviewer queue with full context; policy decisions stay with the named human owner regardless of confidence.
The practical reason for this hybrid is latency and resilience. Field operators making time-sensitive decisions in construction cannot wait for a round-trip to the central system on every routine case. The edge layer handles the routine with the central layer's policies pre-distributed. When connectivity drops, the routine work continues; exceptional cases queue for connection. When connectivity returns, the queue clears, the central log is updated, the analytics catch up. The operation degrades gracefully instead of breaking sharply, which is the property field operators actually need from a workflow that touches their daily work.
The hardest design question in construction data analytics engagements is where to draw the boundary between the digital system and the physical operation. Cross that boundary too far in either direction and the workflow breaks: too digital and field operators ignore it, too physical and the analytics layer cannot tell what is happening at scale.
We draw the boundary at the decision interface. The AI-native workflow ingests sensor data, system records, operator notes, customer signals, and external context. It surfaces the relevant subset to the decision-maker — usually an operator with physical-world context — with the supporting evidence pre-assembled. The operator's decision is captured, executed in the system of record (BIM or adjacent), and logged for the next iteration of calibration. The system does not pretend to know things it does not know; the operator does not have to relay things the system already has.
The architecture choice that follows is data-locality. For construction, the data that matters lives in three places: the central system of record, the field-edge devices, and the operator's head. The first two are connectable; the third is captured through the reviewer interface and the operator notes layer, which we treat as a first-class data source rather than a free-text afterthought. By month six of Run, the operator notes have become a structured corpus that the retrieval layer queries — your field team's accumulated craft, finally legible to the analytics layer.
The risk we explicitly engineer against in construction is the workflow that optimizes the dashboard at the expense of the field. We see this failure mode often in vendor-led AI deployments: the metrics look great, the operators are silently working around the system, the operation degrades. The instrumentation we ship reports both — central metrics and field-feedback signals — so leadership can detect the gap if it opens.
Week-by-week shape of the Build phase
The Build phase rhythm for data analytics in construction is engineered for the bottleneck most teams hit at the end of week 2: ambition outrunning evidence. We engineer for the opposite — evidence first, ambition calibrated to it.
Week 1 produces the discovery report, the labelled test set, the integration plan, the risk register, the success metrics. Week 2 stands up the retrieval index, the intake classifier, the eval harness, the audit log. Week 3 wires the action layer with reviewer approval, runs the first three eval cycles, produces the first calibration report. Week 4 ships the thin slice to a narrow production audience (5-10% of routine cases), instruments the operator feedback loop, and runs the first weekly review.
By day 30, the dashboard is live, the system is processing real construction cases, the operator team is engaging with the reviewer queue, the eval harness is gated on every change, and the next two weeks of Build are scoped from concrete evidence rather than initial assumptions. Days 31-45 widen the production envelope to 40-60% of routine cases. Days 46-60 absorb the remaining routine envelope and start handling the first tranche of exceptional cases. By the close of Build (day 60-70), the workflow is operating at its target envelope with the calibration discipline in place to handle drift, edge cases, and future model changes.
Week 1 — Discovery handover and labelled test set capture. We sit with the operator team running data analytics today, watch a working day end to end, and capture 200+ real cases as the labelled test set. By Friday we have the workflow map, the system inventory (BIM, ERP, and adjacent), the risk register, and the success metrics aligned with your KPI of time to insight.
Week 2 — Architecture and integration scoping. We design the four-layer workflow (intake, context, action, review), confirm the retrieval shape, lock the prompt strategy direction, and produce the integration plan against BIM. The output is the Build statement of work with a fixed price and a named deliverable per phase.
Week 3-4 — Build sprint 1: retrieval and intake. We stand up the retrieval index against your approved sources, build the intake classifier, instrument the audit log, and run the first eval cycle against the labelled test set. The thin slice is functional but not production-deployed.
Week 5-6 — Build sprint 2: action and review. We ship the action layer, build the reviewer queue UI, calibrate the confidence thresholds against the labelled test set, and onboard the first reviewer cohort. By end of week 6 the workflow is processing low-stakes production traffic with full audit logging.
The rest of the Build phase widens the production envelope case-by-case based on the reviewer feedback loop. By the end of Build, data analytics for construction is running on real traffic with the operating cadence already established.
A working example of this pattern
A comparable engagement worth knowing about for data analytics in construction is summarised below. Identity withheld under engagement NDA; sector and stack are accurate.
AI-powered interior design platform — generative room concepts for the MEA market. Vertical AI SaaS for interior design in the Middle East: image-conditioned generation tuned for local taste profiles, room-by-room concept workflow, project export for designers and clients. Built with a market-specific dataset and an evaluation loop on regional aesthetic baselines. (AI interior design SaaS · MEA region, Q1 2026.)
What carries over is the operating discipline — the labelled test set as foundational artefact, the weekly evaluation cadence, the audit log architecture, the reviewer-queue UX. What we re-scope is the integration surface specific to construction (BIM and the adjacent systems) and the prompt strategy tuned to the data analytics vernacular in your category.
For US buyers
US compliance scaffolding for data analytics in construction (NIST AI RMF)
Construction engagements touching US clients on data analytics ship with the regulatory scaffolding your procurement, compliance, and legal teams expect. The framework that matters most for construction is NIST AI Risk Management Framework (AI 100-1) (NIST AI RMF) — addressed below alongside the adjacent frames we encounter.
NIST AI RMF
NIST AI Risk Management Framework (AI 100-1)
Authority: U.S. National Institute of Standards and Technology
- Scope
- Voluntary framework: Govern, Map, Measure, Manage functions for AI system risk.
- How we ship inside it
- Every engagement maps to NIST AI RMF during Discovery. The control map produced becomes the artefact your internal audit and security teams use to defend the workflow.
For US companies
Start a US-friendly engagement
Discovery from $8,500–$12,000, Build from $35,000–$75,000, optional Run from $5k/mo. Fixed-price, milestone-billed, you own every artefact. Send a short brief and we reply within 5 business days. 11am–4pm ET overlap for live syncs.
USD pricing
Discovery $8,500–$12,000 · Build $35,000–$75,000
US-style commercial
MSA / SOW / mutual NDA standard. DPA with SCCs included.
Limited capacity
We onboard 3–5 new clients per quarter to protect delivery quality.
Build internally or work with us
Construction teams that build successfully in-house tend to have an existing ML platform, a labelled data culture, and a product manager dedicated to the workflow. If any of those is missing, the project tends to stall at proof-of-concept. We replace those three dependencies with a scoped engagement and a senior delivery team.
What to ask us before signing
- Ask for a 30/60/90-day plan with named deliverables, not a vague phase description.
- Ask how we handle the long tail of edge cases the operator team has never encoded — escalation, calibration, capture.
- Ask for the model and provider strategy — single-model, multi-model, fallback paths, cost forecasting.
- Ask how the reviewer queue UX is designed and whether your operator team can shape it during Build.
- Ask for references from construction-adjacent engagements — sector, scope, and outcome dimensions.
Recommended first project
Our recommendation for a first data analytics engagement in construction is to pick the slice of the workflow that satisfies four criteria: there is a measurable baseline, the work is genuinely repetitive, the failure mode is reversible within a reasonable window, and a senior operator on your team can be the first reviewer. Those four criteria filter out the engagements that look impressive in a slide and fail in week three. The 90-day target is "thin slice in production with a defended baseline". By day 30, the system processes a small share of real traffic with full reviewer oversight. By day 60, the share has widened and the calibration is data-driven. By day 90, the operating cadence is your team's, the dashboard reflects empirical performance, and the case for the next workflow writes itself.
Frequently asked questions
How do you automate data analytics in construction with AI?+
We map the existing data analytics workflow inside construction, identify the high-volume, high-structure tasks, and build an AI agent that handles those tasks while routing low-confidence cases to a human reviewer. The build connects to your BIM, ERP, project management, runs against a labelled test set, and ships behind a reviewer queue before it sees production traffic. We then operate it, measure time to insight, dashboard adoption, decision cycle time, and anomaly response, and improve it weekly.
What does it cost to automate data analytics for construction teams?+
~$34k–$60k typical year 1 (60% take the run option for ~6 months). The structure: $6k Discovery (2-week sprint) → $22k–$30k Build (7-10 weeks) → optional $3k–$5k / mo Run. Source curation, retrieval architecture, evaluation harness, and decision dashboards.
What is the best AI agent for data analytics in construction?+
Model selection on data analytics for construction happens against five criteria: quality on your labelled test set, cost per inference at your projected volume, latency budget for the user-facing path, provider reliability over 12-18 months, contractual data-handling posture. We bring the comparative methodology from prior engagements and run it during Build; the winning model is the one that survives all five, not the one that wins the demo.
How long does it take to deploy AI data analytics for construction?+
A thin-slice deployment in 2-week sprint after Discovery, with real construction data and real reviewers. The full Build phase runs 7-10 weeks. By day 90, time to insight, dashboard adoption, decision cycle time, and anomaly response is instrumented, the team has a baseline, and leadership has the data needed to decide on expansion into adjacent construction workflows.
What do we own, and what do you own?+
What we ship as code lives in your repository under your IAM. The prompts, the evaluation harness, the integration code, the reviewer UI, the infrastructure-as-code — all in your Git, not in our SaaS. We bring the engineering, the operating discipline, and the cadence; you bring the data, the policy, and the operator team. The handover is documented from day one of Build, not deferred to the end.
How fresh does the source corpus stay?+
Source freshness is a Run-phase deliverable, not a Build-phase promise. The retrieval index is refreshed on a documented cadence (weekly to monthly depending on source velocity), with stale-source detection in the eval harness. When a source goes stale enough to degrade quality, the eval harness catches it before users do.
Do you train models on our data?+
No. We do not train any model on client data. Anthropic Zero-Data-Retention is enabled by default; OpenAI default-no-training is honoured. Prompts, retrieval indexes, audit logs, and integration data live in your cloud account under your IAM. At engagement end, every artefact transfers to your repository.
What if we want to exit the engagement?+
Discovery and Build are fixed-scope, so there is no mid-engagement exit cost. Run is month-to-month with 30-day notice. Every artefact (prompts, eval harness, integration code, dashboards, runbooks) is in your repository throughout the engagement, not behind our SaaS. There is no lock-in.
What does success look like 90 days after Build closes?+
time to insight, dashboard adoption, decision cycle time, and anomaly response measurably improved against the Discovery baseline. Your team is operating the workflow with the cadence we shipped during Build. The audit log is queryable. The reviewer queue is calibrated. The next workflow scope is informed by real production evidence rather than initial assumptions.
What support is included after the engagement ends?+
Optional Run retainer covers weekly cadence, prompt refresh, retrieval index updates, and reviewer-queue calibration. Architecture-level questions and breaking-change support are billed hourly outside of Run. Most engagements transition Run in-house at month 6-12; we stay available for architecture decisions for 12 months at no extra charge.
How does this integrate with BIM and our existing stack?+
Discovery scopes the integration footprint explicitly. We integrate at the API layer; no replatforming required. The Build statement of work names exactly which systems are connected, which data flows are bidirectional, and what authentication patterns we use (SSO, service accounts, OAuth scopes). The integration code lives in your repository.
What does your team look like during an engagement?+
Discovery: 1 senior delivery lead + 1 PM, ~30 hours/week. Build: 1 senior delivery lead + 2-3 senior AI engineers, ~50-80 hours/week across the team. Run: 1 delivery owner + 1 engineer on weekly cadence. We do not use offshore staff augmentation. Every engineer touching your engagement is senior-level.
Sources we reference
The following sources inform the architecture, governance, and benchmarks we apply on construction engagements. Cited here so you can verify and dig deeper.
- NIST Construction
- AI Index Report — Stanford HAI
- The State of AI — McKinsey & Company
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — Lewis et al., Meta AI Research
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., Stanford
- Google Search Central: helpful, reliable, people-first content
- Google Search Central: URL structure best practices
High-intent reads
Start the engagement
Start a Construction engagement
Tell us about your workflow, the systems involved, and the KPI you want to move. We'll send a scoped statement of work within 5 business days.